Editorialist solution was the best method. I used it in the competition and it took me just 0.7 sec to pass the question with a AC.
Link: CodeChef: Practical coding for everyonelink text
Please accept if considered correct. ![]()
2 Likes
I used the method outlined in the editorialist’s solution and got AC:
https://www.codechef.com/viewsolution/18766440
But then I thought of this test case:
1 2 3 4 5 6 7 8 9 10 11
12 1 1 1 1 1 1 1 1 1 13
14 15 16 17 18 1 19 20 21 22 23
24 1 1 1 1 1 1 1 1 1 25
26 27 28 29 30 1 31 32 33 34 35
36 1 1 1 1 1 1 1 1 1 37
38 39 40 41 42 1 43 44 45 46 47
48 1 1 1 1 1 1 1 1 1 49
50 51 52 53 54 1 55 56 57 58 59
60 1 1 1 1 1 1 1 1 1 61
62 63 64 65 66 67 68 69 70 71 72
There’s a 1 connecting each of the rows of 1s, so the entire sea of 1’s should be traversed for each edge that we start a BFS on, right?
That would make this worst case O(N^2 * M^2)?
Maybe I’m missing something here, let me know if it is so. Thanks!
6 Likes
Woah, I actually tried both the approaches. Got AC(100 pts) with Edge based Graph traversal!
1 Like
If Question level is Medium then why added to practice easy section instead of adding to practice medium…
otherwise it will demotivate beginner, who is looking to solve easy problems
9 Likes
Please any one can tell me,
[1]
It is showing TLE again and again.
Any Optimization ?
[1]: https://www.codechef.com/viewsolution/18854836I agree with akamoha. I was actually trying to pass subtask 1 when I got AC. My code would’ve done akamohas test case in O(n*m), but if one modified the 1 to a number greater than all the numbers 1’s connected to, like 100, it would take O(n^2m^2). This is because I only did the dfs if the second number was greater than the first, just like how it’s mentioned in the editorial.
2 Likes
in the tester solution , there is a function
ull get_c(int c1, int c2) {
if(c1 < c2) return (1ULL*c1 << 32) | c2;
else return (1ULL*c2 << 32) | c1;
}
Can anyone tell me the reason why we are doing this?
Getting Confused with these lines
“If, each edge connecting adjacent cells in the grid, whether having same numbers or different numbers if traversed at most twice while determining the size, the complexity will be O(8∗n∗m) overall.”
what i am underStanding,(i know, i am understanding too much wrong):-
if i have total k types of flowers, then total types pairs will be k(k-1), and for each pair it will traverse each edge atmost twice… and total edges are m * n… then complexity should be (k*(k-1))2m * n…
please help, its getting very difficult to for me understand this editorial/Problem/Solution
below is what i did,…
Output
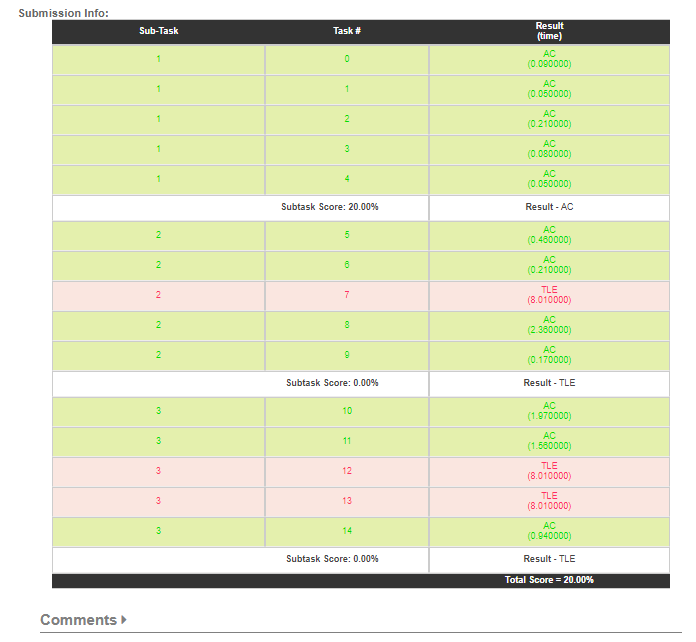
Can i Optimse myCode further…
1 Like
i have seen editorialist solution
https://s3.amazonaws.com/codechef_shared/download/Solutions/JUNE18/editorialist/TWOFL.cpp
lets take test case
1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1
2 3 4 5 6 7 8 9 10
if we consider this type of test case, Time complexity will lead to N.N.M or even to M^2.N^2 so i think we cant exactly say complexity for this solution is N.M
2 Likes
@likecs I also did edge based traversal and I am pretty confident my solution is O(n * m * log(n * m)) at worst case. My idea is , I first labelled cells, consecutive cells having same color gets same label. Now merging these same labelled cells together to form a single node, I have a graph where each edge is connected to 2 different colored nodes. Also one important thing to notice, a edge will be visited atmost once. Also as an edge is visited atmost once, total number of nodes visited is 2 * no_of_edges. So net complexity remains (n * m * log(n * m)) i guess? Can you please share the counter case or prove anyway my solution is n^2 * m^2? Because it did just pass under time limit after a lot of TLES.
Edit:here is the implementation for the same
Can anybody explain me what does
if (rand() & 1) {
swap(xx, yy);
}
mean in Author’s solution? And why is it being used here?
I have a method to share but,the problem with my method was that it only fetched me 40 points,it did not pass the last test cases. But, I tried my best to optimize my code as much possible.
Method :- During input I counted frequency of every elements in matrix. Then I created 2 maps xyz & ank. xyz map stored the cumulative count of pair combination and ank is for marking visited cell for particular pair. Example take pair of (1,2) and let frequency of 1 be 10 and frequency of 2 be 20. So when first time path of (1,2) will occur xyz will store the count of (1,2). Suppose in first path (1,2) contains 15 elements. So, when next time (1,2) path is possible then it will check frequency(1+2) - xyz(1,2) > tot.Here, tot is maximum count variable which will keep getting updated throughout the execution.If condition satisfies then only it will do DFS traversal.
In above @akamoha test case freq of 1=50 and other elements =1. So, count for (1,2)=51. But now it will not do DFS traversal for any other pair as frequency condition won’t satisfy.
It’s a type of brute force but I will highly appreciate if anyone can tell where to optimize my code.
My method = CodeChef: Practical coding for everyone
1 Like
I did not use BFS/DFS - just DSU for the set of all the cells in the field along with subset sizes. First, join all same type pairs of neighbors and save a copy of the resulting data. Then do the following - break the set of all the (unordered) pairs of different neighbor types into subsets in such a way that no two pairs in a subset have a common type. For each subset maintain a hash set of all the types in it and a list of index pairs of neighbors. Maintain a hash map mapping a pair of types into a subset. For each pair of different type neighbors add their indices to the corresponding list. The first time a pair of types is encountered find a subset that contains neither of the two types. If no such subset exists create a new one.
For each of the resulting lists perform union of all the pairs in it restoring to the saved state before processing each list. Maintain the maximal size when performing unions.
Here is python (PyPy) solution.
UPDATE.
This solution got AC, but it will be slow for a case when there is a type with a large number of different neighbor types. Instead we can simply maintain a hash map of separate lists for each pair of neighbor types, and at each DSU iteration restore only those elements that have been changed, as described in the editorial.
1 Like
I used just dfs and it fetched me 80 points…i was getting tle in one of the test cases of 2nd subtask.
In dfs , what i did was…i just fixed one number and counted the connecting components of all other numbers ansd the fixed number connected to it which are greater (maintaining each ones count in a map) …thus i was able to count each pair’s connected component in just one dfs run . Also i have used many optimisations to prevent tles … but still i was getting one tle .
However , finally using some conditions (which i thought could have been the reason for the tle )…i was able to get 100 points (though i am not satisfied by my approach).
But still i want to know why i was getting tle in the 2nd subtask’s 3rd test case …if anyone could help ![]()
Here is my solution .
1 Like
I formed the components as in the author’s solution and then used the edge base graph traversal instead of dsu.The edges here are the edges of the component graph.I feel in this way we can guarantee the bound to be O(8*N*M) what was tried to achieve in the editorialist’s solution.
2 Likes
https://www.codechef.com/viewsolution/18897826
I need help. Actually I don’t know it is due to StackOverflow and I can’t resist to avoid it.
@likecs: I think there should be a correction in the pseudo code given for the first subtask. I think it should be:
if vis[i][j] or (a[i][j] != c1 and a[i][j] != c2):
Correct me if I’m wrong. But I think this is correct.
3 Likes
Can anyone please explain how did we calculate the time complexity of “DSU + sorting map” solution since it has loops and we have to reset values evertime after we perform union find on components?
TIA!
for (auto &vec : ed) {
vector < int > changed;
for (auto &it : vec.second) {
int x = it.first, y = it.second;
changed.push_back(x);
changed.push_back(y);
int xx = getWho(x), yy = getWho(y);
if (xx == yy) {
continue;
}
if (rand() & 1) {
swap(xx, yy);
}
who[xx] = yy;
sz[yy] += sz[xx];
ans = max(ans, sz[yy]);
}
for (auto &it : changed) {
sz[it] = sizes[it];
who[it] = it;
}
}
**can someone explain how this DSU part works in author’s solution??
In short , what is use of getWho() function and who[] array??**Being new to competitive programming, and knowing nothing about the methods described here (or at least not by the abbreviations used), I developed a completely different method based on my previous experience of flood-filling. This scored me 100 points, completing in 1.66 seconds. If anyone is interested please see my submitted solution (in C#), or ask me to explain it further here.
1 Like