PROBLEM LINK:
Author: Konstantin Sokol
Tester: Tasnim Imran Sunny
Editorialist: Praveen Dhinwa
DIFFICULTY:
HARD
PREREQUISITES:
heavy light decomposition, segment tree
PROBLEM:
There are N persons in Mike’s school. No person in the school has a name(except Mike), but all of them have a unique ID number for the range[1…N].
Mike’s ID equals to 1. Also, each person(except Mike) has his/her personal idol, who is another person from the school.
Finally, each person has a number A[X].
Let’s define functions F and G for a person:
If X = 1(which means that person X is Mike), then F X = A X and G X = 1;
Otherwise, let Y be the personal idol for X.
If F[Y] + 1 < A X , then F X = A X and G X = 1
If F[Y] + 1 > A X , then F X = F Y + 1 and G X = G Y
If F[Y] + 1 = A X , then F X = F Y + 1 and G X = G Y + 1
It’s guaranteed, that it’s possible to calculate functions F and G for every person in the school.
You are to write a program, that can efficiently process queries of the following types:
0 X V : change the value of A X to V
1 X : calculate F X and G X
QUICK EXPLANATION
The line “It’s guaranteed, that it’s possible to calculate functions F and G for every person in the school.” and constraint in the problem that
P i < i ensures that graph is a rooted tree at the root 1.
What does F[X] correspond to ?
F X = max(A y + depth[X] - depth[y]) where y is a vertex on the path from root to X.
What does G X correspond to ?
Let M = max(A y - depth[y]) where y is a vertex on the path from root to X.
F X = number of nodes such that A[y] - y = M where y is a vertex on the path from root to X.
So now we can do heavy light decomposition of the tree and can answer the queries using a simple segment tree over the heavy edges.
EXPLANATION
The line “It’s guaranteed, that it’s possible to calculate functions F and G for every person in the school.” and constraint in the problem that
P i < i, ensures that graph is a rooted tree at the root 1. Each node corresponds to a person and each edge of the graph
denotes the personal idol relationship between two persons. Formally, if person X has personal idol Y, then there would be an edge from Y to X.
Note that the graph is tree with N nodes. Also note that root node has no personal idol.
Interpretation of F X
Let us view the following picture to get the idea how can we compute F.
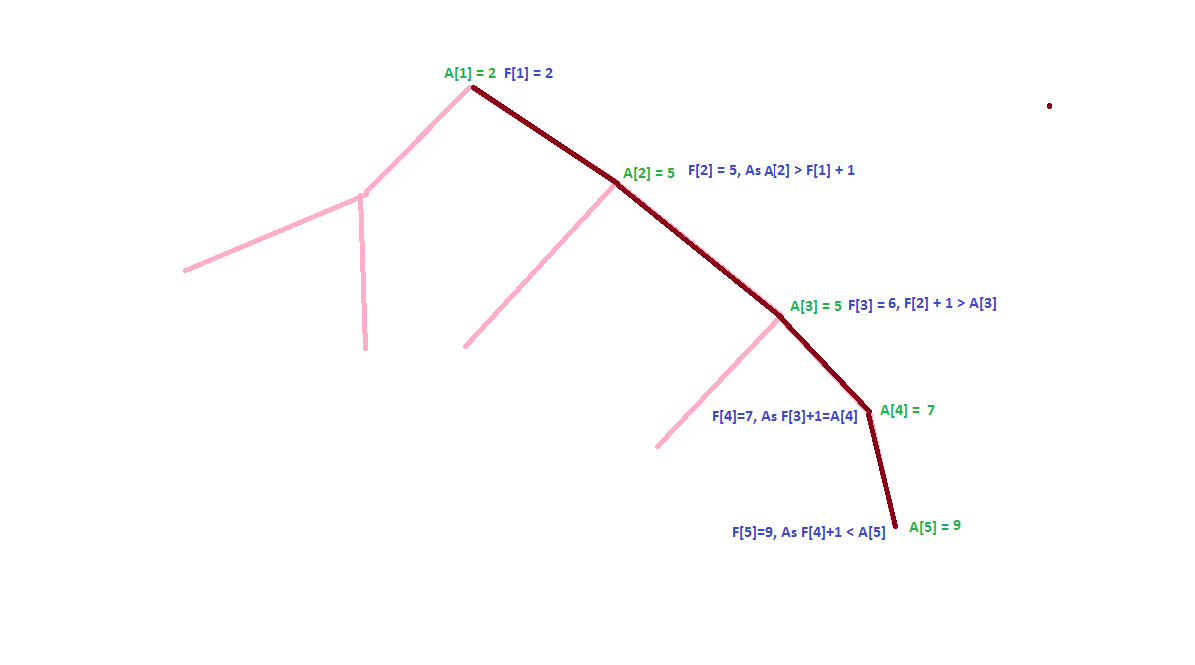
Let us understand definition of F[X].
Note that F[1] will be same as A[1]. What about F[X] for other than 1?
If A[X] > F[Y] + 1, then F[X] = A[X], It means that if value of A is larger than previous F[Y] + 1, then our current F[X] will be A[X].
Otherwise F[X] = F[Y] + 1, it means F[X] will increase by 1.
Note the following properties of function F.
-
F is a strictly increasing function, because at each step, we can see that F will increase by at least 1.
If A[X] > F[Y] + 1, then it will increase by more than 1. -
Also note that F[X] will always be greater than or equal to A[X].
-
For computing F[X], we need to start from root and go to X, So let us say during this movement, we are currently at vertex y, then we
can say that F[X] should be at least A[y] + distance between X and y. (because we go down from parent to child, then at each step, we will increase value of F by atleast 1).
By using the previous properties, we can now say that
F X = max(A y + distance between X and y) where y is a vertex on the path from root to X.
Note that in a tree, distance between two nodes is equal to difference in depths of those nodes. So distance be X and y will be depth[X] - depth[y].
So F X = max(A y + depth[X] - depth[y]) where y is a vertex on the path from root to X.
As for a fixed X, depth[X] is fixed, so we can take depth[X] out of the expression.
So F X = depth[X] + max(A[y] - depth[y]) where y is a vertex on the path from root to X.
Interpretation of G X
Claim:
Let M = max(A y - depth[y]) where y is a vertex on the path from root to X.
Then, G X = number of nodes such that A y - y = M where y is a vertex on the path from root to X.
Proof Ideas
Note the following properties of function G.
- G[X] will increase only if F[Y] + 1 = A[X].
ie. if depth[Y] + max(A[y] - depth[y]) + 1 = A[X] (As F[Y] = depth[X] + max(A[y] - depth[y]).)
ie. if depth[X] + max(A[y] - depth[y]) = A[X] (As depth[X] = depth[Y] + 1)
ie. max(A[y] - depth[y]) = A[X] - depth[X].
Intiuitively, it means that if value of A[X] - depth[X] is equal to maximum value of A[y] - depth[y], then we will increase the count by 1.
- G[X] will be reset to 1, if value of A[y] - depth[y] is strictly greater than previous values.
Intiuitively, it means that we have found new value of max(A[y] - depth[y]), so we reset the count of max(A[y] - depth[y]) to 1.
- if value of A[X] - depth[X] is not the maximum of A[y] - depth[y], then value of G remains constant, the value of G[X] = G[Y].
Intiuitively, it means that if the current value of A[y] - depth[y] is less than max(A[y] - depth[y]), then it won’t affect
the max(A[y] - depth[y]) and it will also not effect the count of maximum value of A[y] - depth[y]. So count will remain constant.
Using these observations you can get an intuition that these three operations correspond to updating the count of
the number corresponding to the maximum of A[y] - depth[y].
How to deal with given queries
Assume that our tree is just a chain. Then we can use segment tree to answer our queries.
Our node structure of the segment tree will contain two values max_val : the max value of A[v] - v and cnt: the count of the
maximum value.
node {
int max_val;
int cnt;
}
As the most important step in answering the queries in segment tree is how we are going to merge answer of the two nodes
of the segment tree.
node merge(node a, node b) {
if (a.max_val > b.max_val) {
return a;
}
if (a.max_val < b.max_val) {
return b;
}
// then cnt of maximum will be a.cnt + b.cnt,
// because both a.max_val and b.max_val are equal.
node new_node(a.max_val, a.cnt + b.cnt);
}
Heavy Light Decomposition of a tree (HLDOT)
(This part of the explanation is taken from editorial of problem QUERY)
If you can solve the problem for a chain using a segment tree, then there is a very good chance that you can solve the problem for a tree using HLDOT. Indeed, if you make segment trees over the heavy edges, then the answer for your path X-Y can be broken up into two paths from X to LCA(X, Y) and from Y to LCA(X, Y). Then, using that you make only logN shifts from one heavy-chain to another, you are actually making only log(N) segment-tree queries.
In our case, either X or Y is 1. So lca is always root node. So we dont need to compute LCA explicitly.
The heavy-light decomposition is used to break up a Tree into s set of disjoint paths, with certain useful properties. First, root the tree. Then, for each vertex x, we find the child of x having the largest subtree. Lets call that vertex y. Then the edge x-y is a heavy edge, and all other x-child_vertex edges are light edges.
The most important property of this is, from any vertex x, the path from x to the root goes through at most logN different light-edges. This is because, on this path, whenever you take a light edge, you are atleast doubling the size of the subtree rooted at the new vertex. Hence you cannot perform this “doubling” effect more than logN times.
Stack overflow Issue
While testing the problem, the contest panel found the issue that recursive solutions for HLDOT, were getting stack overflow error in C++ 4.8
and C++ 11 whereas surprisely working fine in C++ 3.4.2. In one of the test cases, the depth of the tree was 83267, the DFS crashed on the depth 60000. but was working fine on 50000. So if your solution is getting run time error, it is advised to write your recursive dfs using
an explicit stack. In MSC++, you can also increase the stack limit programmatically. Though in C++, you can increase the stack size programmatically too, but it can only be done on your local machine for testing. Please share and discuss some ways of increasing stack size in
various programming languages.
Complexity
Complexity will be O(N + Q * (log N)^2). As noted in the explanation, the maximum number of light edges from root to any code can be at most log N.
For each heavy path, we will query the segment tree over the heavy path in O(log N) time, So we can have at most log N queries to the segment tree.