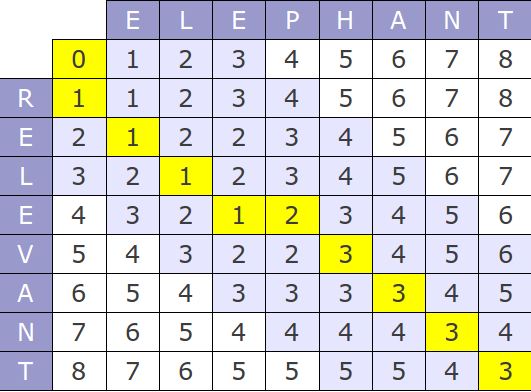
If no more than k differences should be found. In this case it is necessary to calculate only the diagonal band of width 2k+1 in matrix (Ukkonen cut-off), which reduces the time complexity to O (k min (m, n))
I think this figure is best to visualize the idea.
k step right and k step left to the main diagonal will do.
Why is this problem tagged as Easy-Medium in the editorial tag? I think it should be marked at least as Medium because it requires pre-requisite knowledge of a popular dynamic programming algorithm and then we need to optimize it further.
The reason why I am pointing this out is that several users who start off with competitive programming on Codechef, start solving problems from the Easy subpart in the Practice Section. It can be demotivating for a user if he/she is unable to solve the problem even though it is in the so-called “Easy” Section.
I guess it is very common that even some rather difficult problems are marked as Medium.
Of course, difficulty is relative, it differs from person to person. However, some problems like this one are definitely not Easy.
Could anyone point out what’s wrong with my solution? I’m getting a TLE. I used Ukkonen’s Algorithm for my approach. I’m using a single array to store the edit distances and a temporary variable to store the value of what would be d[i-1][j-1], if the O(N2) approach with the d[0…m][0…n] matrix is used. I seem to have missed something and I haven’t been able to figure it out yet.
How you generated some let say random inputs, but with known result to test your algorithm?
Because of small k I thought, that I can use this:
Both input string should be in form of
...S1...S2...S3...SN...
where S1, S2, … SN are some common substrings and “…” is some mess.
To find longest substring I wanted to use DP, which is unfortunately O(n2) (n is the length of longer string), so I decided I can try to find those in segments of 400 characters (if there is not common string result is -1).
When I did this I simply replaced S1, …, SN with characters that were not in initial strings and run “find longest common subsequence algorithm” also O(n2) algorithm, but now for string with length of ~200 characters…
Expected complexity something like 100400400 + 200*200 per test case, but I didn’t get to TLE, because it worked on my PC, but was failing for some test cases.
I’m trying to solve this problems with above idea, but I get WA, I don’t know what’s wrong with my code?
Here is my code : CodeChef: Practical coding for everyone
Could anyone give me a hint why I’m wrong?
Thank you! ^^
I referenced this diagram (@ http://i.stack.imgur.com/2LtnD.png) instead for my implementation (which turns out to be WA) is there a way to reconcile the two? meaning how should I setup the for-loops to iterate the correct bounds as necessary to compute the final answer?

{kind=link}