What is the approach to solve KILLER problem from the May Long Challenge 17?
3 Likes
I didn’t have enough time to solve it, but it should be possible to solve it by doing a post-order DFS on the tree, while maintaining a kinetic binomial heap over all potential brushes. The binomial heap would allow fast merging on nodes with more than one child and allow you to query the currently cheapest brush.
You will have add some extra fields to the data structure to allow fast adding a constant to the heaps that are getting merged.
Different from a regular priority queue, you would actually never remove anything from the heap, but always often query the cheapest brush and look at your certificates to update the order of the brushes while moving closer to the root.
Kinetic heap: https://en.wikipedia.org/wiki/Kinetic_heap
The “time” here is the depth of your current node. As you move closer to the root, some initially expensive brushes, will get cheaper than other options.
I can only solve for the case when the tree is just a line. For that case, you can write down the dp problem and the naive iteration will give you O(n^2) but you can apply some convex optimization trick to get O(nlog n). For detail, please check:
convex optimization
I think my solution is a bit of an overkill, but I’ll share it anyway. I heard some people were able to solve this linearly, I’m quite interested so do leave some comments if you’re one of them.
Short Summary
Use convex hull trick in a persistent segment tree, to minimize quadratic equations. Traverse subtrees using heavy-light decomposition. Solution runs in O(N log^2 N).
Solution
Let D_u = h - dep_u.
Define f as the cost of adding the path (u,v), where v is the deeper node:
f(u, v) = \sum_{w\in path(u,v)}{(C_vD_w + {C_v}^2)} - H_v
= C_v(\frac{D_u(D_u+1)}{2}-\frac{D_v(D_v-1)}{2})+{C_v}^2(D_u-D_v+1)-H_v
= {D_u}^2\frac{{C_v}}{2} + D_u(\frac{C_v}{2} + {C_v}^2)- \frac{C_vD_v(D_v-1)}{2} + {C_v}^2(1-D_v) - H_v
Notice how the only entities with u are D_u. Fix v, then for every v we have a quadratic equation:
f_v(x)= {x}^2\frac{{C_v}}{2} + x(\frac{C_v}{2} + {C_v}^2)- \frac{C_vD_v(D_v-1)}{2} + {C_v}^2(1-D_v) - H_v
Notice how quadratic equations are increasing with positive x since C_v >= 0.
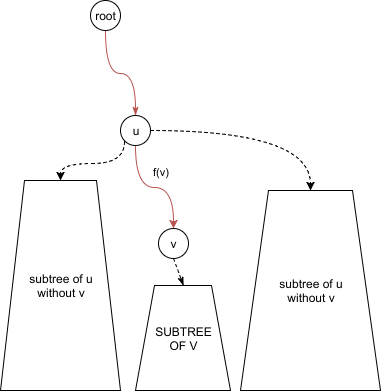
Tree structure
We can use f_v equation to get the value of any node on the path from the root to v. Just plug-in f_v(D_u). The red path shows where we can use f_v:
DP Solution O(n^2)
Define dp(v) as the answer for the whole subtree rooted at v. Before we calculate this, we should shift the parabola f_v by the answer we have for its children:
f_v(x) := f_v(x) + \sum_{w \in child(v)}{dp(w)}
Let S(u,w) be the sum of solutions of the children of u excluding w:
S(u,w) = \sum_{w' \in child(u) \setminus \{w\}}{dp(w')}
Then we can compute for dp(u):
dp(u) = min\{f_u(D_u)\}\cup\{f_v(D_u) + S(u, w) \ |\ w \in child(v), v \in subtree(w)\}
The answer is dp(1). Traversing each subtree takes O(N) time, and there are N nodes so the total time is O(N^2). This passes subtasks 1 and 2.
Convex Hull Trick
We can improve the solution by using the convex hull trick. The goal is instead of iterating through each parabola in the subtree, we want to perform insert/update operations for the log factor. This time is that we are doing this with parabolas and not lines.
There are a couple of ways to do this, mine might not be the best. We can do this with any binary search tree, like a splay tree or a multiset. In my case I used ternary search on a segment tree. Before you violently react with “what the heck is a ternary search on a segment tree!”, I’ll explain how I modeled the segment tree.
Notice how every query operation is on an int. Let the segment tree contain the information about the minimum parabola at coordinate x, which can be up to the depth of the tree (10^5).
Query: Go down the segment tree and get the parabola at index x.
Insert: This is the tricky part. Let F be our set of parabolas (represented by the segment tree). Consider absolute value |F(x) - f_v(x)|.
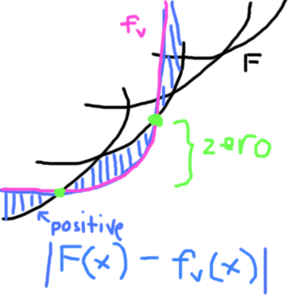
Outside the intersection, the formula has positive value. At the intersection, this formula is 0. If we want to insert a new parabola f_v, we search for the intersection. There can be upto 2 intersections, and that range is where f_v belongs. We can do this in many ways, in my case I did ternary search to find the intersection, since the formula is bitonic and ternary search gives the minimum.
Wait, ternary search on a segment tree???
We are searching with ints, so instead of splitting (L,R) to (\frac{2L+R}{3}, \frac{L+2R}{3}), we can instead split by (\lfloor{\frac{L+R}{2}}\rfloor, \lfloor{\frac{L+R}{2}}\rfloor+1). Yep, ternary search the “binary search” way. (see CF post on Ternary Search hoax)
Now that we have the tree, we can solve subtask 3 in O(N log N). With the same dp(u) formula, we can skip traversing the whole subtree and instead use the tree for a point query.
Heavy-light decomposition + Persistence
For the convex hull trick to work for a whole tree, we need a way to “pass” a segment
tree of parabolas to the parent efficiently. We need to “merge” all parabolas of a node’s subtree. But right now, even if we make our segment tree persistent, the best we can do still more than O(N^2) time since merging whole subtrees is costly.
This is where HLD comes in. The idea of HLD is to mark a “heavy child” per node in the tree. The heavy child, as its name suggests, is the child with the most descendants. What’s useful about the heavy child? In our traversal, we start by “claiming” the heavy child
as the current subtree. After that, we traverse the light children and “merge” them one by one. HLD Theorem claims that if we do it this way, the “merging” becomes O(N log N) time total (proof). Truly the magic we need. The code snippet below shows that part:
void dfs(int u, int parent) {
// ... omitted
// copy the heavy tree (note, this should be persistent)
segment_tree[u] = segment_tree[heavy[u]];
// merge light nodes one-by-one
for (int v : adj[u])
if (v != parent && v != heavy[u])
for (int w : subtree[v])
segment_tree[u].insert(parabola(w));
// ... omitted
}
Complexity
After merging, we can perform a query to update the dp function. HLD adds log N factor,
while each insert operation is O(log N). For N nodes, the total running time
is O(N log^2 N).
Btw, this is NOT the official solution editorial, but pardon it for being editorial-like, I can’t explain it effectively otherwise. I don’t know if my solution matches the intended solution, but I hope that was helpful ![]()
10 Likes
I was thinking I would need something like hikarico’s solution. However, what was intended to be an intermediate solution that probably should have TLE’d somehow worked.
Start with hikarico’s DP O(n^2) solution. Imagine that you are solving this DP bottom-up. If we are trying to solve f(x), x will use some node n as the endpoint of its path, where n can be x or a node in the entire subtree of x. If n has a C value of C(n), you can prove the following fact: any other nodes q in x’s subtree that have C(q) >= C(n) will NEVER be chosen as the endpoint for any of x’s parents. Thus as you go up the tree, you remove such nodes from consideration. So I maintained a vector of nodes under consideration, with a simple O(n) merge + filtering operation. This is O(n^2) worst-case. But the solution passes all the tests in time; I guess the test cases were weak enough for this to succeed.
2 Likes
Could you please elaborate your answer? Are u using “Convex Hull Optimization1” in that table?
If so, how are you writing the Dp in the form M*X+C?
Can you please explain how do you use ternary search for finding intersection points of parabola and convex hull??
@hikarico “I did ternary search to find the intersection, since the formula is bitonic and ternary search gives the minimum.” - How is the formula given bitonic, it looks like a bimodal function to me with two minimums at 0.
Also in the segment tree, what information was stored in each node
Unlike the usual convex hull optimization, my dp was of the form ax^2+bx+c which is a quadratic equation. Fortunately it was increasing since all coefficients were positive, so I was able to represent it “similar” to the original mx + c optimization.
@hikarico Can you suggest any resources to study heavy-light decomposition and persistent segment trees?