PROBLEM LINK:
Author: Sergey Nagin
Tester: Jingbo Shang
Editorialist: Ajay K. Verma
DIFFICULTY:
Easy-Medium
PREREQUISITES:
Dynamic programming, Edit Distance
PROBLEM:
Given two strings, and and integer k, determine if the edit distance between the two strings exceeds k, and if not, then also compute the edit distance between the two strings.
EXPLANATION:
We are given a string s, which we want to transform into another string w using the following three operations:
- add a character at any position , cost = a
- delete a character, cost = a
- replace a character, cost = b
The goal is to minimize the cost, and if the cost exceeds a given value k, then return -1. Note that if a = 0, then the answer will be zero, as we can remove insert/delete any character in the first string at zero cost. From now onwards, we will assume that a > 0.
This is a standard edit-distance problem, which can be solved using dynamic programming in O (N2) time, where N is the size of the string. However, in our case N is too large and the Wagner–Fischer algorithm of quadratic complexity will run out of time. However, there is a special constraint here, which is that we need to compute the edit distance only if it does not exceed k. This can be used to reduce the complexity to O (Nk).
In order to understand the modification, we first need to understand the Wagner–Fischer algorithm, which we highlight very briefly in the next section. If you are unaware of this algorithm, please take a moment to go through the above mentioned link.
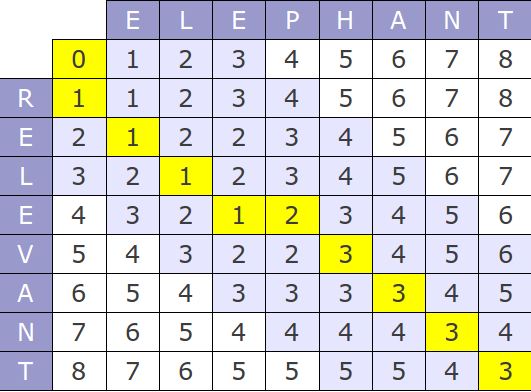
Wagner–Fischer algorithm:
Suppose of the of string s is m, and the size of string w is n, then we create a two dimensional array d[0…m][0…n], where d[i][j] denotes the edit distance between the i-length prefix of s and j-length prefix of w.
The computation of array d is done using dynamic programming, which uses the following recurrence:
d[i][0] = i * a, for i <= m
d[0][j] = j * a, for j <= n
d[i][j] = d[i - 1][j - 1], if s[i] == w[j],
d[i][j] = min(d[i - 1][j] + a, d[i][j - 1] + a, d[i - 1][j - 1] + b), otherwise.
Restricted Edit Distance:
We can modify the definition of array d[][], a little bit.
d[i][j] = inf, if the edit distance between the i-length prefix of s and j-length prefix of w exceeds k,
d[i][j] = edit distance between the i-length prefix of s and j-length prefix of w, otherwise.
Note that if (i - j) > k, then we need to delete more than k characters from the first string, hence, the edit distance will be greater than k * a >= k. Similarly, if (i - j) < -k, then we need to add more than k characters in the first string, which will again have a cost greater than k * a >= k. Hence, d[i][j] = inf, if |i - j| > k
This means we only need to compute the values d[i][j], where |i - j| <= k. All other values in the array has to be infinite. There are only O(N * k) such entries, hence the complexity reduces to O (Nk).
For simplicity, we can use another array P[0…N][-k…k], such that
P[i][delta] = d[i][i + delta]
We are using negative indices only for simplicity, an offset can be used to make the indices non-negative.
The recurrence for P can be written easily using the recurrences for d.
P[i][- i] = i * a, for i <= k
P[0][i] = i * a, for i <= k
P[i][delta] = P[i - 1][delta], if s[i] == w[i + delta]
P[i][delta] = min(P[i - 1][delta + 1] + a, P[i][delta - 1] + a, P[i - 1][delta] + b), otherwise
In the recurrence, one should use the value inf, if delta goes outside the range [-k, k].
If the difference between the length of the two strings is more than k, then the answer will be -1, otherwise answer will be P[s.length()][w.length() - s.length()]. Once again, it should be checked if the final answer exceeds k, if so then we should return -1 instead.
Time Complexity:
O (Nk)
AUTHOR’S AND TESTER’S SOLUTIONS:
Author’s solution will be put up soon.
Tester’s solution will be put up soon.