PROBLEM LINK:
DIFFICULTY:
Medium-Hard
PREREQUISITES:
Trees, Segment tree, DFS order
PROBLEM:
You are given a rooted tree with N nodes. If you select a node u, then all nodes in u’s subtree with distance \le K will be covered. For each K from 1 to N, find the minimum number of nodes to select to cover all nodes and return the sum.
QUICK EXPLANATION
A greedy solution of always selecting the K-th ancestor of the deepest uncovered node is correct. We can prove that the sum of answers is O(N\log N), so we will perform each greedy step in O(\log N) time with segment tree operations, making the total time complexity O(N \log ^2 N).
EXPLANATION:
Let’s consider the deepest uncovered node u. Somehow, we need to cover it, so one of the K+1 ancestors of u should be selected (including u). Which of those K+1 ancestors do we select?
Observation 1. If v is an ancestor of u with distance \le K, then after selecting v, all nodes in v’s subtree will be covered.
Proof
u is the deepest uncovered node, so all other uncovered nodes in the subtree of v are closer to v and given that v has a distance \le K from u, v will also have a distance \le K from all uncovered nodes in v’s subtree.
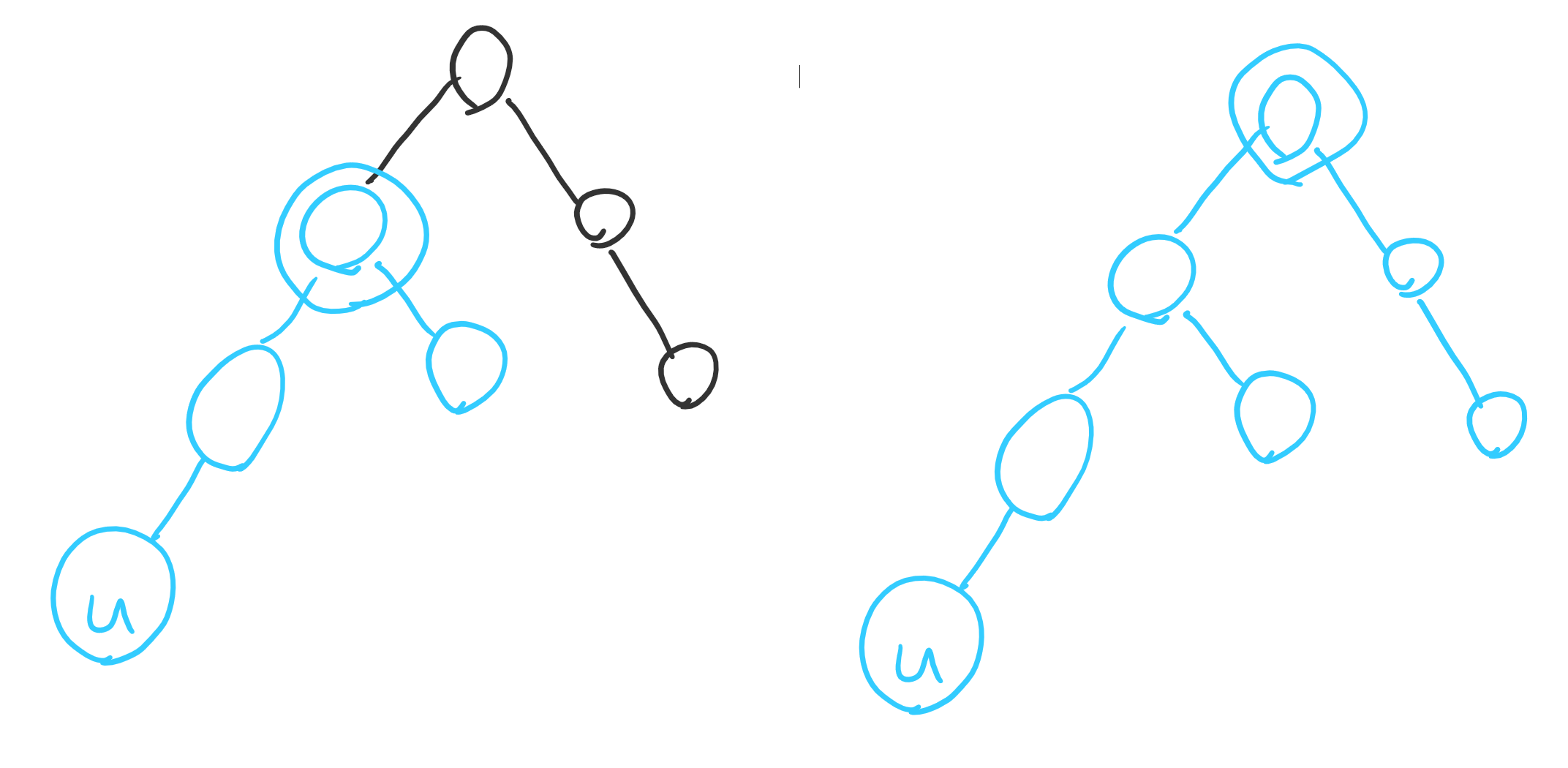
Observation 2. It is always optimal to select the K-th ancestor (or the root if there is no K-th ancestor) of the deepest uncovered node.
Proof
It is always better to select a higher ancestor that can still cover u because the uncovered nodes of a higher subtree is a superset of the uncovered nodes in the lower subtree.
Using observations 1 and 2, we can formulate a simple greedy solution, shown below:
- While there exists an uncovered node:
- Find the deepest uncovered node and let it be u.
- Let v be the K-th ancestor of u or the root if u has no K-th ancestor.
- Select v and cover all nodes in v’s subtree.
Observation 3. The sum of answers is O(N \log N).
Proof
Every time we select v, we cover at least the nodes on the path from u to v, which covers at least K+1 uncovered nodes (except for the case when v is the root).
So the answer for each K is at most \frac{N}{K+1}+1. It is well-known that the sum of this expression over all K is O(N \log N) (it can be proven easily with calculus).
This means that if we can somehow perform each greedy step in O(\log N), then we will have a total time complexity of O(N \log^2 N).
Finding the K-th ancestor of u in O(\log N) is standard and the most common way to solve it is using Binary Lifting. This leaves us with 1. finding the deepest uncovered node and 2. covering the entire subtree of v efficiently.
Subtree queries are a sign that we should use DFS preorder to reduce the subtree queries into range queries on an array. After applying DFS preorder, our queries are 1. finding the node with maximum depth on the entire array and 2. setting a range of nodes to -1 (to simulate covering the nodes). To support these two queries in O(\log N), we just need a segment tree which supports range maximum queries and range set updates.
There’s one last thing: At the start of calculating the answer for each K, we need to undo the changes from covering the nodes while calculating the answer for the previous K. Note that rebuilding the segment tree naively for each K is not an option because it will cause the entire solution to be O(N^2). One simple (if you already know persistent segment trees well enough) solution is to just use a persistent segment tree. Another way you could uncover the nodes is to store the changes you make to the segment tree array and recover them before calculating the next K. Check my implementation for more details.
SOLUTIONS:
Setter's Solution
//+-- -- --++-- +-In the name of ALLAH-+ --++-- -- --+ \\
#include <iostream>
#include <algorithm>
#include <fstream>
#include <vector>
#include <deque>
#include <assert.h>
#include <queue>
#include <stack>
#include <set>
#include <map>
#include <stdio.h>
#include <string.h>
#include <utility>
#include <math.h>
#include <bitset>
#include <iomanip>
#include <complex>
#define F first
#define S second
#define _sz(x) (int)x.size()
#define pb push_back
using namespace std ;
using ll = long long ;
using ld = long double ;
using pii = pair <int , int> ;
const int N = 1e5 + 20 ;
int n , ans = 0 ;
int st[N] , ft[N] , h[N] , tme , per[N] ;
vector <int> g[N] , vec[N] ;
struct node {
int mxh , v = -1 ;
int lazy ;
int hish , hisv ;
} seg[N << 2] ;
void clear() {
ans = tme = 0;
for (int i=0; i<n; i++) st[i] = ft[i] = h[i] = per[i] = 0;
for (int i=0; i<n; i++) g[i].clear(), vec[i].clear();
for (int i=0; i<4*n; i++) seg[i].mxh = seg[i].lazy = seg[i].hish = seg[i].hisv = 0, seg[i].v = -1;
}
void pre_dfs (int v , int par = -1) {
st[v] = tme ++ ;
per[st[v]] = v ;
vec[h[v]].pb(v) ;
for (int u : g[v]) {
if (u == par) continue ;
h[u] = h[v] + 1 ;
pre_dfs(u , v) ;
}
ft[v] = tme ;
}
#define lc (v << 1)
#define rc (lc ^ 1)
#define mid (s + e) >> 1
void change (int v , int val) {
seg[v].mxh = val ;
seg[v].lazy = val ;
}
void shift (int v) {
if (seg[v].hish == -1) seg[v].hish = seg[v].mxh , seg[v].hisv = seg[v].v ;
if (seg[v].lazy == -1) return ;
change(lc , seg[v].lazy) ;
change(rc , seg[v].lazy) ;
seg[v].lazy = -1 ;
}
void modify (int l , int r , int val , int v = 1 , int s = 0 , int e = n) {
if (e - s == 1) seg[v].v = per[s] ;
if (seg[v].hish == -1) seg[v].hish = seg[v].mxh , seg[v].hisv = seg[v].v ;
if (r <= s || e <= l) return ;
if (l <= s && e <= r) {
change(v , val) ;
return ;
}
shift(v) ;
modify(l , r , val , lc , s , mid) ;
modify(l , r , val , rc , mid , e) ;
seg[v].mxh = max(seg[lc].mxh , seg[rc].mxh) ;
if (seg[lc].mxh == seg[v].mxh) {
seg[v].v = seg[lc].v ;
}
else {
seg[v].v = seg[rc].v ;
}
}
void rst (int v = 1 , int s = 0 , int e = n) {
if (seg[v].hish == -1) return ;
seg[v].mxh = seg[v].hish ;
seg[v].v = seg[v].hisv ;
seg[v].lazy = -1 ;
seg[v].hish = -1 ;
seg[v].hisv = -1 ;
if (e - s == 1) return ;
rst(lc , s , mid) ;
rst(rc , mid , e) ;
}
inline int get (int h , int s) {
int low = -1 , high = _sz(vec[h]) ;
while (high - low > 1) {
int md = (low + high) >> 1 ;
if (st[vec[h][md]] <= s) low = md ;
else high = md ;
}
return vec[h][low] ;
}
void solve() {
cin >> n ;
for (int i = 0 , u , v ; i < n - 1 ; i ++) {
cin >> u >> v ;
u -- , v -- ;
g[u].pb(v) ;
g[v].pb(u) ;
}
h[0] = 1 ;
pre_dfs(0) ;
for (int i = 0 ; i < n ; i ++) modify(st[i] , st[i] + 1 , h[i]) ;
for (int i = 0 ; i < (n << 2) ; i ++) seg[i].hish = seg[i].hisv = seg[i].lazy = -1 ;
for (int k = 1 ; k <= n ; k ++) {
int cnt = 0 ;
while (seg[1].mxh != 0) {
cnt ++ ;
ans ++ ;
int v = seg[1].v ;
int u = get(max(1 , h[v] - k) , st[v]) ;
assert(st[u] <= st[v] && ft[v] <= ft[u]) ;
modify(st[u] , ft[u] , 0) ;
}
//if (k % 1000 == 0) cerr << ' ' << k << ' ' << cnt << endl ;
rst() ;
}
cout << ans << '\n' ;
}
int main(){
ios::sync_with_stdio(false) , cin.tie(0) , cout.tie(0) ;
int t; cin >> t;
while(t--) {
solve();
clear();
}
}
Tester's Solution
#include <bits/stdc++.h>
#include <vector>
#include <set>
#include <map>
#include <string>
#include <cstdio>
#include <cstdlib>
#include <climits>
#include <utility>
#include <algorithm>
#include <cmath>
#include <queue>
#include <stack>
#include <iomanip>
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/tree_policy.hpp>
//setbase - cout << setbase (16); cout << 100 << endl; Prints 64
//setfill - cout << setfill ('x') << setw (5); cout << 77 << endl; prints xxx77
//setprecision - cout << setprecision (14) << f << endl; Prints x.xxxx
//cout.precision(x) cout<<fixed<<val; // prints x digits after decimal in val
using namespace std;
using namespace __gnu_pbds;
#define f(i,a,b) for(i=a;i<b;i++)
#define rep(i,n) f(i,0,n)
#define fd(i,a,b) for(i=a;i>=b;i--)
#define pb push_back
#define mp make_pair
#define vi vector< int >
#define vl vector< ll >
#define ss second
#define ff first
#define ll long long
#define pii pair< int,int >
#define pll pair< ll,ll >
#define sz(a) a.size()
#define inf (1000*1000*1000+5)
#define all(a) a.begin(),a.end()
#define tri pair<int,pii>
#define vii vector<pii>
#define vll vector<pll>
#define viii vector<tri>
#define mod (1000*1000*1000+7)
#define pqueue priority_queue< int >
#define pdqueue priority_queue< int,vi ,greater< int > >
#define flush fflush(stdout)
#define primeDEN 727999983
mt19937 rng(chrono::steady_clock::now().time_since_epoch().count());
// find_by_order() // order_of_key
typedef tree<
int,
null_type,
less<int>,
rb_tree_tag,
tree_order_statistics_node_update>
ordered_set;
int timer=0;
int intim[123456],outim[123456];
int dep[123456];
int paren[123456][20];
vector<vi> adj(123456);
int rev[123456];
int dfs(int cur,int par){
int i;
intim[cur]=timer++;
rev[timer-1]=cur;
if(par==-1){
dep[cur]=0;
}
else{
dep[cur]=dep[par]+1;
}
paren[cur][0]=par;
rep(i,adj[cur].size()){
if(adj[cur][i]==par)
continue;
dfs(adj[cur][i],cur);
}
outim[cur]=timer-1;
return 0;
}
int kthpar(int u,int k){
int i;
if(dep[u]<=k)
return 0;
fd(i,19,0){
if((1<<i)<=k){
u=paren[u][i];
k-=(1<<i);
}
}
return u;
}
pii wow[412345],seg[412345];
int lazy[412345];
int build(int node,int s,int e){
lazy[node]=0;
if(s==e){
wow[node]=mp(dep[rev[s]],rev[s]);
seg[node]=wow[node];
return 0;
}
int mid=(s+e)/2;
build(2*node,s,mid);
build(2*node+1,mid+1,e);
wow[node]=max(wow[2*node],wow[2*node+1]);
seg[node]=wow[node];
return 0;
}
int update(int node,int s,int e,int l,int r,int val){
if(lazy[node]!=0){
if(s!=e){
lazy[2*node]=lazy[node];
lazy[2*node+1]=lazy[node];
}
if(lazy[node]==1){
seg[node]=wow[node];
}
else{
seg[node].ff=-1;
}
lazy[node]=0;
}
if(r<s || e<l)
return 0;
if(l<=s && e<=r){
if(val==1){
seg[node]=wow[node];
}
else{
seg[node].ff=-1;
}
if(s!=e){
lazy[2*node]=val;
lazy[2*node+1]=val;
}
return 0;
}
int mid=(s+e)/2;
update(2*node,s,mid,l,r,val);
update(2*node+1,mid+1,e,l,r,val);
seg[node]= max(seg[2*node],seg[2*node+1]);
return 0;
}
int main(){
std::ios::sync_with_stdio(false); cin.tie(NULL);
int t;
cin>>t;
while(t--){
timer=0;
int n;
cin>>n;
int i;
int u,v;
rep(i,n){
adj[i].clear();
}
rep(i,n-1){
cin>>u>>v;
u--;
v--;
adj[u].pb(v);
adj[v].pb(u);
}
int j;
dfs(0,-1);
f(j,1,20){
rep(i,n){
if(paren[i][j-1]==-1)
paren[i][j]=-1;
else
paren[i][j]=paren[paren[i][j-1]][j-1];
}
}
int ver;
build(1,0,n-1);
int ans=0;
f(i,1,n+1){
while(seg[1].ff!=-1){
ans++;
ver=kthpar(seg[1].ss,i);
update(1,0,n-1,intim[ver],outim[ver],-1);
}
update(1,0,n-1,intim[0],outim[0],1);
}
cout<<ans<<endl;
}
return 0;
}
Editorialist's Solution
#include <bits/stdc++.h>
using namespace std;
#define ar array
const int mxN=1e5;
int n, dt, ds[mxN], de[mxN], anc[mxN][17];
vector<int> adj[mxN];
ar<int, 2> st[1<<18];
vector<pair<int, ar<int, 2>>> ch;
//set a[l1] = x
void upd1(int l1, ar<int, 2> x, int i=1, int l2=0, int r2=n-1) {
if(l2==r2) {
st[i]=x;
return;
}
int m2=(l2+r2)/2;
if(l1<=m2)
upd1(l1, x, 2*i, l2, m2);
else
upd1(l1, x, 2*i+1, m2+1, r2);
st[i]=max(st[2*i], st[2*i+1]);
}
//set a[l1..r1] = {0, -1}
void upd2(int l1, int r1, int i=1, int l2=0, int r2=n-1) {
//store original
ch.push_back(make_pair(i, st[i]));
if(l1<=l2&&r2<=r1) {
st[i]={0, -1};
return;
}
int m2=(l2+r2)/2;
if(l1<=m2)
upd2(l1, r1, 2*i, l2, m2);
if(m2<r1)
upd2(l1, r1, 2*i+1, m2+1, r2);
st[i]=max(st[2*i], st[2*i+1]);
}
void dfs(int u=0, int p=0, int d=0) {
anc[u][0]=p;
for(int i=1; i<17; ++i)
anc[u][i]=anc[anc[u][i-1]][i-1];
upd1(dt, {d, u});
ds[u]=dt++;
for(int v : adj[u])
if(v^p)
dfs(v, u, d+1);
de[u]=dt;
adj[u].clear();
}
void solve() {
//input
cin >> n;
for(int i=1, u, v; i<n; ++i) {
cin >> u >> v, --u, --v;
adj[u].push_back(v);
adj[v].push_back(u);
}
//calculate necessary info with dfs
dt=0;
dfs();
int ans=0;
//simulate each k
for(int k=1; k<=n; ++k) {
for(; ; ++ans) {
//find deepest
ar<int, 2> u=st[1];
if(u[1]<0) {
//no nodes left
break;
}
//find ancestor
for(int i=16; ~i; --i)
if(k>>i&1)
u[1]=anc[u[1]][i];
//cover ancestor
upd2(ds[u[1]], de[u[1]]-1);
}
//restore changes
for(; ch.size(); ch.pop_back())
st[ch.back().first]=ch.back().second;
}
cout << ans << "\n";
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
int t;
cin >> t;
while(t--)
solve();
}
Please give me suggestions if anything is unclear so that I can improve. Thanks ![]()
