Here’s the Problem Statement.
Consider a M x N, two dimensional Grid. Two types of cells are defined - Blocked Cell and Free Cell, i.e., any cell is either blocked or free. Consider all Possible paths from top left cell (1,1) to bottom right cell (M,N) such that, at any cell, you can move either to the cell on its right, or to the cell below it. Now we define a special cell. A Special cell is a free cell such that, if it is blocked, then no path exists from (1,1) to (M,N). You are given the representation of grid in the form of a matrix where 1 represents a free cell and 0 represents a blocked cell. Find the probability that, if you pick a free cell, it is also a special cell.
Output Format: Say you can represent the Probability in the form of P/Q. Print P x Q^{-1} Modulo 10^9+7
Constraints: 1 \le M,N \le 10^3
Example input:
10 10
1110011001
1011100100
1101100010
0110100000
0011111000
0100010101
1000011011
0000001111
0000101011
0000101111
Example Output:
956521746
Explanation:
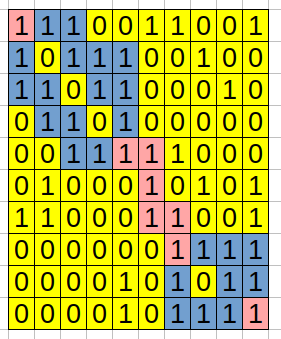
Non-Yellow cells constitute all possible paths from (1,1) to (10,10).
Cells in Pink represent Special Cells.
There are 46 Free Cells in total and 8 Special Cells in total. So, Probability is 8/46, viz., 4/23.
Now, The answer is (4 \times inverse(23)) \% (10^9+7)., viz., 956521746.
Any approach to solve this?
 ) it’s clean enough for you to read. Just ping me once if you don’t get the idea I’ll be happy to explain. Again sorry for wasting your time yesterday.
) it’s clean enough for you to read. Just ping me once if you don’t get the idea I’ll be happy to explain. Again sorry for wasting your time yesterday.