PROBLEM LINK:
Practice
Div-2 Contest
Div-1 Contest
Author: Vivek Chauhan
Tester: Suchan Park
Editorialist: William Lin
DIFFICULTY:
Medium
PREREQUISITES:
Combinatorics
PROBLEM:
There are N points, the i-th point is at (i, A_i). All A_i are uniformly randomly generated from 1 to M. For all 0\le i \le N-2, segment i connects points i and i+1. You are given Q queries (l, r), meaning that you need to calculate the maximum height (|A_i-A_{i+1}|) of a segment in [l, r). You can ask at most K questions of the form (x1, x2, y) and you will be given the maximum height of a segment in [x1, x2) which intersects with the horizontal line at y.
QUICK EXPLANATION 1:
Output M-1 for all queries.
EXPLANATION 1:
For subtask 1, K=3 while Q=10, so it’s impossible to even ask 1 question per query! This prompts us to think whether we even need to ask any questions.
The constraint R-L \ge 1000 is really weird. It tells us that there are a lot of segments in the query. Generally, constraints in competitive programming are upper bounds, not lower bounds.
Also, M\le 10 is very small. It kind of makes sense that there should be at least one segment with height M-1 (which is the maximum height) within those 1000 segments.
This is a long challenge, we can submit solutions without any sort of proof, so why not submit a solution which outputs M-1 for all queries? Turns out, it gets AC!
Let’s analyze the probability that the answer is not M-1 for some query and let’s call it x. Let’s first calculate the probability that the height of some segment is not M-1. There are M^2 possibilities for choosing the first and second points for the segment. The only two possibilties when the segment can have a height of M-1 are (1, M) and (M, 1). The probability that we want is y=1-\frac{2}{M^2}.
Note that we can’t just say that x=y^{R-L} because the segments are not independent of each other. However, every other segment is independent, so we can ignore the segments between every other segment and say that x<y^{\frac{R-L}{2}}. If we calculate y^{\frac{R-L}{2}}, we find that it is around 4\cdot 10^{-5} for M=10.
QUICK EXPLANATION 2:
For each query (L, R), we will ask the question (L, R, \frac{M}{2}) and the answer of the question will be the answer of the query.
EXPLANATION 2:
For subtask 2, K=10 while Q=10, so we can ask 1 question per query.
The constraint R-L \ge 100 still tells us that there are a lot of segments in the query, so some randomization will probably be required again.
M=10^9, so unlike the previous subtask, we can’t just say that the answer for each query is M-1.
Our strategy will be to hit as many segments as possible with 1 question, and we will hope that the maximum height we get from this question will be the maximum height of the segments in the range of the query.
To hit as many segments as we can in the range, we should have x1=L and x2=R. What about y?
If we choose y=1 (which is the minimum possible value of A_i), then the line is unlikely to intersect with any of the segments. So, it makes sense that as we move the line towards the middle of 1 and M, the line will be able to intersect with more segments.
Our solution for this subtask is to, for each query (L, R), ask the question (L, R, \frac{M}{2}). We can submit this simple solution and find out that it gets AC!
We want to prove that the line y=\frac{M}{2} will intersect the segment with the greatest height with a high probability. Notice that any segment with height greater than \frac{M}{2} will intersect the line y=\frac{M}{2}. Let’s instead prove that the line with the greatest height will always have a height greater than \frac{M}{2}.
Again, if the probability of failure is x, then we know that x<y^\frac{R-L}{2}, where y is the probability that a segment does not have a height greater than \frac{M}{2}.
We can define y more precisely: y is the probability that when we choose real numbers 0 < a, b < M (M is big so we can just treat the numbers as reals), |a-b|<\frac{M}{2}. We can scale down by M, so we are choosing real numbers 0 < a, b < 1 and we want the probability that |a-b|<\frac{1}{2}.
We can find y with geometric probability:
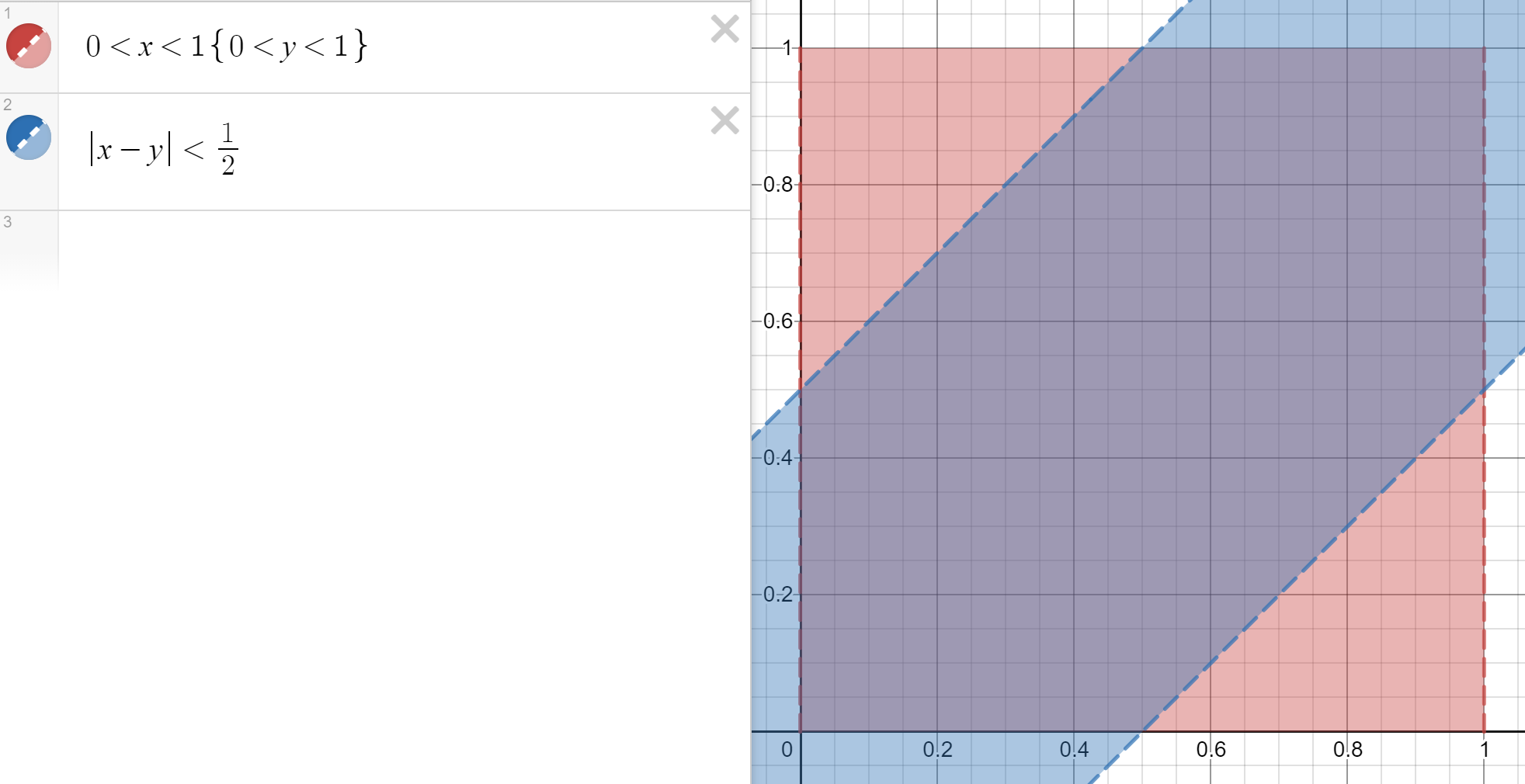
The red square represents all (a, b) with 0 < a, b < 1. The blue region represents all (a, b) with |a-b|<\frac{1}{2}. y is the fraction of the area of the red square that is also covered by the blue region. We can calculate that fraction to be \frac{3}{4} (the two triangles have a combined area of \frac{1}{4}).
Lastly, we plug in the numbers and calculate \left (\frac{3}{4} \right)^{50}, which is around 6 \cdot 10^{-7}.
SOLUTIONS:
Setter's Solution
#include <bits/stdc++.h>
using namespace std;
void solve() {
//input
int n, m, limit, q;
cin >> n >> m >> limit >> q;
int l[q], r[q], ans[q];
for(int i=0; i<q; ++i)
cin >> l[i] >> r[i];
if(limit<q) {
//subtask 1
for(int i=0; i<q; ++i)
ans[i]=m-1;
} else {
//subtask 2 & 3
for(int i=0; i<q; ++i) {
cout << "1 " << l[i] << " " << r[i] << " " << (1+m)/2 << endl;
cin >> ans[i];
}
}
cout << 2<<" ";
for(int i=0; i<q; ++i)
cout << ans[i] << " ";
cout << endl;
cin>>q;
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
int t;
cin >> t;
while(t--)
solve();
}
Tester's Solution
#include <bits/stdc++.h>
void run() {
int N, M, limit, Q;
assert(scanf("%d%d%d%d", &N, &M, &limit, &Q) == 4);
std::vector<int> L(Q), R(Q), ans(Q, M-1);
for(int q = 0; q < Q; q++) {
int l, r; assert(scanf("%d%d", &l, &r) == 2);
L[q] = l;
R[q] = r;
}
if(N == 2000) {
for(int q = 0; q < Q; q++) {
printf("1 %d %d %d\n", L[q], R[q], int(1e9) / 2);
fflush(stdout);
assert(scanf("%d", &ans[q]) == 1);
}
}
printf("2");
for(int q = 0; q < Q; q++) printf(" %d", ans[q]);
puts("");
fflush(stdout);
int ret;
assert(scanf("%d", &ret) == 1);
if(ret == -1) exit(0);
}
int main() {
#ifndef ONLINE_JUDGE
//freopen("input.txt", "r", stdin);
freopen("input.txt", "r", stdin);
#endif
int T; assert(scanf("%d", &T) == 1);
while(T--) {
run();
}
return 0;
}
Editorialist's Solution
#include <bits/stdc++.h>
using namespace std;
void solve() {
//input
int n, m, limit, q;
cin >> n >> m >> limit >> q;
int l[q], r[q], ans[q];
for(int i=0; i<q; ++i)
cin >> l[i] >> r[i];
if(limit<q) {
//subtask 1
for(int i=0; i<q; ++i)
ans[i]=m-1;
} else {
//subtask 2 & 3
for(int i=0; i<q; ++i) {
cout << "1 " << l[i] << " " << r[i] << " " << (1+m)/2 << endl;
cin >> ans[i];
}
}
cout << 2;
for(int i=0; i<q; ++i)
cout << " " << ans[i];
cout << endl;
cin >> q;
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
int t;
cin >> t;
while(t--)
solve();
}
Please give me suggestions if anything is unclear so that I can improve. Thanks ![]()