PROBLEM LINKS
DIFFICULTY
MEDIUM
PREREQUISITES
String Matching, Aho-Corasick, Dynamic Programming
PROBLEM
You are given a dictionary D, of W words.
You are given a set of N strings, S, to search for the frequency of occurance of the W words.
EXPLANATION
This is a classical problem in multiple string searching.
If the task gave a single word, then using Knuth-Morris-Pratt would have yeilded linear time complexity. But, repeating the same approach for each word will lead to O(summa(|strings in D|) + W * summa(|strings in S|)) computations, which is too much for the time limit.
The indended solution requires the use of the Aho-Corasick string matching algorithm. The idea is that you build a data structure for all the given set of words in O(summa(|strings in D|)) computations. This can then be used to search for each occurance of any of the words in the strings in S.
This is primarily an extension of the Knuth-Morris-Pratt structure’s failure function, where you allow transitions across different strings on failure - called the suffix arc in the wikipedia article.
The wikipedia article is quite informative and contains further links to help you with implementing this datastructure, including, links to implementation in C.
The time complexity of using the Aho-Corasick algorithm to find each match is O(summa(|strings in D|) + summa(|strings in S|) + summa(frequency of each word)).
The sum of the frequencies of the words is quite large.
count the frequency of words
Thus, we cannot look for individual matches and add them up. We do a clever dynamic programming on the Aho-Corasick data structure.
- It is important to understand the meaning of the dictionary suffix arc (the reference .fail on each node in the tester’s code) to understand the remaining discussion.
Aho-Corasick iterates through the matches by backtracking through the data structure while following only the dictionary suffix arcs. Since they lead to matched dictionary words, the complete backtrack prints every match.
The data structure, along with the dictionary suffix arcs, creates a directed acyclic graph which is expected to be traversed to print each match. Since we don’t want to print each match
- we can defer the backtracking by only storing the count of times each node was reached
- lazily update the counts on each node by adding them upwards by following the dictionary suffix arcs
- finally, print the counts on each node representing a matched word
#example
Let us say that there are two words
- ab
- cab
The Aho-Corasick data structure looks like
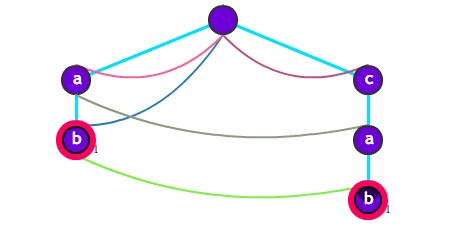
There is one dictionary suffix arc in light green.
We process the string acabbab. When we have processed the first 4 characters, the standard algorithm expects to print cab and then follow the dictionary suffix arc and print ab.
But, we only store a count of 1 on the node b that is reached at cab. We refrain from backtracking at this point. We continue and eventually store 1 when we end up on the node b that is reached at ab.
Later, we follow the links and add up the count values by visiting the graph bottom-up in breadth first manner. This means that we add the 1 at the b in cab to the 1 at the b in ab because they hßave a dictionary suffix arc between them.
Refer to the tester’s solution for details.
SETTER’S SOLUTION
Can be found here.
TESTER’S SOLUTION
Can be found here.