PROBLEM LINKS :
Contest : Division 1
Contest : Division 2
Setter : Jiang XunCi
Tester : Alipasha Montaseri / Kasra Mazaheri
Editorialist : Anand Jaisingh
DIFFICULTY :
Hard
PREREQUISITES :
Binarization of a given tree, Auxiliary tree trick, Centroid Decomposition over edges
PROBLEM :
Given 2 edge weighted graphs G_1 and G_2 consisting of N nodes, you need to find the sum \sum_{i=1}^{N} \sum_{j={i+1}}^{N} f(G_1,i,j) \cdot f(G_2,i,j) , where f(G,x,y) denotes the minimum weight path between nodes x and y in a given graph G.
The weight of a path is the maximum cost of an edge appearing on the path.
QUICK EXPLANATION :
This problem is extremely technical. To make it quick, we can create binary tress from the given input graphs, and then apply some kind of modified Centroid Decomposition over these trees to find the answer in O(N \cdot \log(N))
EXPLANATION :
This editorial is going to be long and complicated, so let’s get directly to it :
Claim 1 :
f(G,x,y) equals the maximum cost edge on the path between nodes (x,y) in any minimum spanning tree of graph G.
Proof :
The condition given in the problem statement, the definition of f(G,x,y) can be re-written as, f(G,x,y) equals the minimum integer k, such that if we only consider edges from graph G with cost \le k , then there exists a path between nodes x and y.
When using Kruskal’s algorithm for the MST of a graph, we can easily see we minimize the maximum appearing on any path between 2 nodes, and the k we’re looking for is the edge cost corresponding to the edge that merges nodes x and y for the first time.
So, the original task now transforms to : Given 2 trees consisting of N nodes, we need to find the sum : \sum_{i=1}^{N} \sum_{j=i+1}^{N} Max_1(i,j) \cdot Max_2(i,j) , where Max_1(i,j) denotes the maximum cost edge between nodes (i,j) in tree 1 and Max_2(i,j) denotes the maximum cost edge on the path between nodes (i,j) in tree 2.
Subtask 1 :
Here , N \le 2000 , and we can find in \log(N) time the value of Max_1(x,y) \cdot Max_2(x,y) for each pair unordered pair (x,y).
The maximum on a path can be found by building a sparse table st, where st[i][j] denotes the maximum cost edge on the path between node j and it’s 2^{i} th ancestor.
We can then using binary jumping easily find the maximum cost edge on the path between nodes x,lca(x,y) and nodes y,lca(x,y). Since there are a total of O(N^2) pairs, the overall runtime is O(N^2 \cdot \log N )
Subtask 2 :
Since the structure of both tree is the same, the final answer shall be \sum_{i=1}^{N} \sum_{j=i+1}^ N Max_1(i,j)^2 . This can be done easily while processing the edges during Kruskal’s algorithm.
The overall runtime is O(N \cdot \log N )
Full Score :
To Proceed further, we present an explanation of each of the per-requisites, and then present the solution.
1. Binarization of a given Tree:
We need to build a binary tree from the given tree that follows the following condition :
- It consists of 2 \cdot N -1 nodes, consisting of exactly N leaves numbered 1,2,...N
- Each edge is weighted, and any path from an ancestor to one of its descendants consists of edge weights in decreasing order.
- The maximum on the path between 2 nodes (i,j) is the same in the given tree and this binary tree.
We can build such a tree as follows :
Sort the given edges as per their weights, and let comp[z]=z \hspace{0.2cm} , 1 \le z \le 2 \cdot N -1 . Now, start processing these edges one by one. When processing the i^{th} edge (u_i,v_i,w_i), add an edge between nodes n+i and comp[u] with cost w_i, and between nodes n+i and comp[v] with cost w_i.
Now, for all nodes x, such that comp[x]=u or comp[x]=v, set comp[x]=n+i
For example, the binary tree for the 1^{st} sample, 1^{st} graph would be:
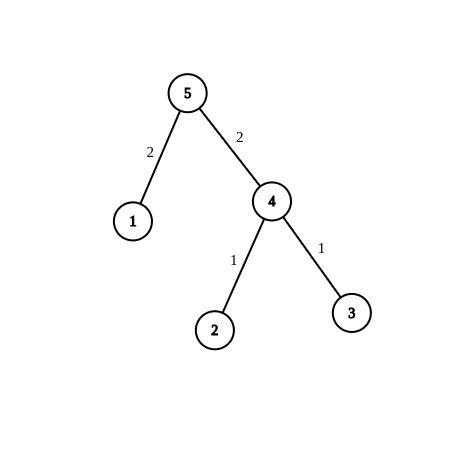
The binarized tree looks the same even for the second sample.
2. Centroid Decomposition over edges :
It’s going to be quite useful to know about standard Centroid Decomposition, to help you read further. You can learn about it here
In Centroid Decomposition over edges, in each move, instead of removing from the current tree a node, we instead remove an edge.
So, the tree splits further exactly into two more trees in each step. The condition on the basis of which an edge is chosen is : we choose an edge, such that the size of the smallest tree this tree further splits into is as large as possible.
Note that if the current tree we are processing consists of Q nodes, the condition above ensures that the sizes of the 2 new trees it splits into is as close to \frac{Q}{2} as possible.
However, in the worst case such a decomposition could lead to O(N^2) solutions. Here is where the binarization comes in. This centroid decomposition over edges works in O(N \cdot \log N ) over binary trees.
The pseudo code for centroid decomposition over edges is something like :

Credit to EtaoinWu for this image
3. Construction of Auxiliary Tree
Given a subset of Q nodes from an original tree T, we need to build an auxiliary tree A following the conditions :
- For all nodes x \in Q , x \in A ,
- For any subset of nodes x_1,x_2,...x_k \in Q , lca(x_1,x_2,....x_k) \in A
- There is an edge between each node in A and it’s closest ancestor from tree T \in A ( Except the root of the auxiliary tree )
It can be proved that after sorting the Q initially given nodes by dfs order ( also called tin order), the lca of any subset of nodes shall be the among the lca of 2 adjacent nodes among the given Q.
We can then easily build the auxiliary tree in O(Q) time using a stack
Solution:
Let’s binarize both the given trees and start centroid decomposition on edges over the first binary tree. Note that we consider both built binary trees to be rooted at node 2 \cdot N -1 .
Let the current tree being processed by the decomposition be T and the edge to be removed
from this tree be E(parent(i),i).
Now, when we remove edge E from tree T, we know T will split into 2 new parts. Let’s call the first among them T_1 ( this is the part parent(i) lies in ) and the second among them T_2 ( this is the part i lies in ).
Also, for each node x \in T such that x is a leaf node ( index \le N ), lets store the maximum cost edge on the path that starts with edge E and ends at it. Let this number be val[x].
Claim:
For all x \in T_2 such that x is a leaf node, val[x]=cost(E) .
Proof :
The binary trees we constructed in such a way that when we traverse the tree from a parent to one of its children, then the cost of the edges on the path between them can only decrease. Now, when we remove the edge (parent(i),i), then all leafs belonging to the same part as i are in the sub tree of i.
Now, over here, we need to sum Max_1(a,b) \cdot Max_2(a,b) , such that a \in T_1 and b \in T_2 .
We can do this as follows :
Build an auxiliary tree using all leaf nodes \in T . Obviously these nodes are the ones having index \le N . However, we build this auxiliary tree using the dfs in out times and lca's of these nodes from the 2^{nd} tree, and not the first.
Then, let’s perform a Dp over this auxiliary in bottom up fashion. When we reach some node u from bottom to top, then we know :
For any 2 nodes (a,b) belonging to different child sub trees of u such that a \in T_1 and b \in T_2, :
Max_1(a,b) = val[a] and
Max_2(a,b) = cost of the edge originating from node u in the second binary tree. This is because both (a,b) belong to sub tree of node u in the second binary tree.
Then this sum is easy to calculate.
The overall time complexity of this approach is O( N \cdot \log(N)), if we calculate lca in O(1), or O(N \cdot \log^2(N)) if we calculate lca's in O(\log(N)).
For example, let’s simulate everything once for better understanding.
Let the MST of the first tree consist of the edges : [(1,2,1),(1,3,4),(2,4,5)]. Then, the binary tree we build is :
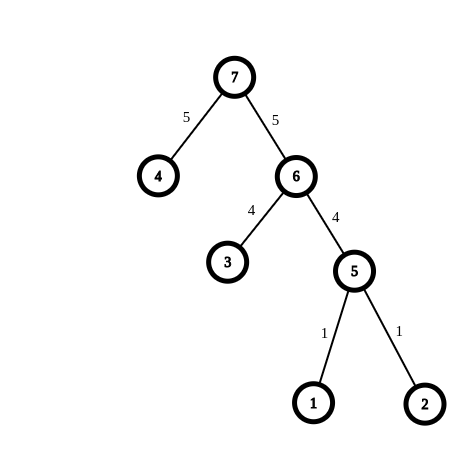
And let the MST of the second tree consist of the edges : [(1,4,2),(4,3,3),(1,2,4)]. Then, the binary tree we build is :
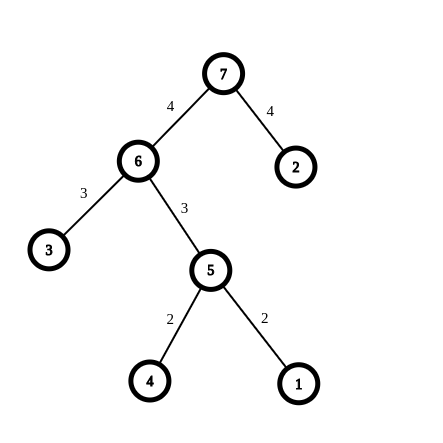
Now, when doing centroid decomposition on edges of the first tree, assume we are going to remove the edge (6,5). Then obviously for all leaf nodes x belonging to sub tree of 5 , val[x]=cost(6,5).
Then, we need to build an auxiliary tree using the leaf nodes (1,2,3,4). This tree is identical to the second binary tree ( Since this is the first step ).
Now, when we reach node 6 in the DP over the auxiliary tree, we know node 1 \in T_1 and node 3 \in T_2 . The max cost edge between them in the second tree will be 3 ( This will hold for all pairs (a,b) belonging to different child sub trees of node 6), and in the first tree, it will be val[3] ( Since node 3 belongs to T_1.
Aaaand we’re done !
I thin most of the techniques presented above are relatively unknown, and I used this blog to learn everything.
The setter’s approach differs significantly, and is based on link cut trees and segment tress.
Your comments are welcome !
COMPLEXITY ANALYSIS :
Time Complexity : O ( N \cdot \log N ) or O(N \cdot \log^{2} N )
Space Complexity : O(N)
SOLUTION LINKS :
Setter
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int maxn = 2e5, mod = 998244353;
int n, m;
int lc[maxn + 10], rc[maxn + 10], w[maxn + 10], sz[maxn + 10];
int fa[maxn + 10];
int ndcnt, res;
ll ans[maxn + 10];
struct edge {
int l, r, w;
bool operator < (const edge &t) const {
return w < t.w;
}
}a[maxn + 10];
int getf(int p) {
return fa[p] == p ? p : fa[p] = getf(fa[p]);
}
void buildtree(int m, int *lc, int *rc, int *w, int *sz, int& ndcnt) {
for (int i = 1; i <= m; ++i)
scanf("%d%d%d", &a[i].l, &a[i].r, &a[i].w);
ndcnt = n;
sort(a + 1, a + m + 1);
for (int i = 1; i <= n; ++i) {
fa[i] = i; sz[i] = 1;
}
for (int i = 1; i <= m; ++i) {
int l = getf(a[i].l), r = getf(a[i].r);
if (l != r) {
if (sz[l] < sz[r]) swap(l, r);
w[++ndcnt] = a[i].w;
fa[ndcnt] = ndcnt;
sz[ndcnt] = sz[l] + sz[r];
lc[ndcnt] = l; rc[ndcnt] = r;
fa[l] = ndcnt; fa[r] = ndcnt;
}
}
}
namespace ooo {
int m, ndcnt;
int lc[maxn + 10], rc[maxn + 10], w[maxn + 10], sz[maxn + 10];
int top[maxn + 10], fa[maxn + 10];
int wt[maxn + 10], a[maxn + 10], rt[maxn + 10], lt[maxn + 10];
int dep[maxn+ 10];
ll allans;
struct tg {
int w1, w2;
}tag1[maxn * 4 + 10], tag2[maxn * 4 + 10];
tg operator + (const tg &a, const tg &b) {
return (tg){a.w1 + b.w1, a.w2 + b.w2};
}
struct data {
ll sall, s1w, s2w, sw;
void add(const tg &v) {
sall += s1w * v.w2 + s2w * v.w1 + sw * v.w1 * v.w2;
s1w += sw * v.w1; s2w += sw * v.w2;
}
}val1[maxn * 4 + 10], val2[maxn * 4 + 10];
data operator + (const data &a, const data &b) {
return (data){a.sall + b.sall, a.s1w + b.s1w, a.s2w + b.s2w, a.sw + b.sw};
}
int ls[maxn * 4 + 10], rs[maxn * 4 + 10], lc2[maxn * 4 + 10], rc2[maxn * 4 + 10], pcnt;
int mi[maxn * 4 + 10];
void update(int p) {
val1[p] = val1[lc2[p]] + val2[lc2[p]] + val1[rc2[p]];
val2[p] = val2[rc2[p]];
}
void build(int &p, int l, int r) {
p = ++pcnt;
ls[p] = l; rs[p] = r;
if (l == r) val2[p].sw = wt[l];
else {
int suml = 0, sumr = 0, mn = 1e9;
for (int i = l; i <= r; ++i) sumr += lt[i];
for (int i = l; i < r; ++i) {
suml += lt[i]; sumr -= lt[i];
int w = max(suml, sumr);
if (w < mn) {
mn = w; mi[p] = i;
}
}
int mid = mi[p];
build(lc2[p], l, mid); build(rc2[p], mid + 1, r);
update(p);
}
}
void apply1(int p, tg v) {
tag1[p] = tag1[p] + v; val1[p].add(v);
}
void apply2(int p, tg v) {
tag2[p] = tag2[p] + v; val2[p].add(v);
}
void push(int p) {
if (tag1[p].w1 || tag1[p].w2) {
apply1(lc2[p], tag1[p]); apply2(lc2[p], tag1[p]);
apply1(rc2[p], tag1[p]);
tag1[p] = (tg){0, 0};
}
if (tag2[p].w1 || tag2[p].w2) {
apply2(rc2[p], tag2[p]); tag2[p] = (tg){0, 0};
}
}
void modify(int p, int l, int r, const tg &v1, const tg &v2) {
if (ls[p] == l && rs[p] == r) {
apply1(p, v1);
apply2(p, v2);
} else {
int mid = mi[p]; push(p);
if (r <= mid) modify(lc2[p], l, r, v1, v2);
else if (l > mid) modify(rc2[p], l, r, v1, v2);
else {
modify(lc2[p], l, mid, v1, v1);
modify(rc2[p], mid + 1, r, v1, v2);
}
update(p);
}
}
void dfs(int p) {
dep[p] = dep[fa[p]] + 1;
top[p] = lc[fa[p]] == p ? top[fa[p]] : p;
if (p > n) {
fa[lc[p]] = p; dfs(lc[p]);
fa[rc[p]] = p; dfs(rc[p]);
}
}
void init() {
buildtree(m, lc, rc, w, sz, ndcnt);
dfs(ndcnt);
for (int i = 1; i <= ndcnt; ++i)
if (top[i] == i) {
int acnt = 0;
for (int j = i; j; j = lc[j]) {
a[++acnt] = j;
lt[acnt] = sz[j] - sz[lc[j]];
wt[acnt] = w[j];
}
build(rt[i], 1, acnt);
}
}
void change(int p, int v) {
while (p) {
int f = top[p];
allans -= (val1[rt[f]] + val2[rt[f]]).sall;
modify(rt[f], 1, dep[p] - dep[f] + 1, (tg){v, 0}, (tg){0, v});
allans += (val1[rt[f]] + val2[rt[f]]).sall;
p = fa[f];
}
}
}
void dfs2(int p, int v) {
if (p <= n) ooo::change(p, v);
else {
dfs2(lc[p], v); dfs2(rc[p], v);
}
}
void dfs(int p) {
if (p <= n) ooo::change(p, 1);
else {
dfs(rc[p]); dfs2(rc[p], -1);
dfs(lc[p]); dfs2(rc[p], 1);
ans[p] = ooo::allans;
res += w[p] % mod * ((ans[p] - ans[lc[p]] - ans[rc[p]]) % mod) % mod;
if (res >= mod) res -= mod;
}
}
int main() {
scanf("%d%d", &n, &m);
ooo::m = m;
buildtree(m, lc, rc, w, sz, ndcnt);
ooo::init();
dfs(ndcnt);
printf("%d", res);
}
Tester
/*
Take me to church
I'll worship like a dog at the shrine of your lies
I'll tell you my sins and you can sharpen your knife
Offer me that deathless death
Good God, let me give you my life
*/
#include<bits/stdc++.h>
#define lc (id << 1)
#define rc (lc ^ 1)
#define md (l + r >> 1)
using namespace std;
const int N = 100005 * 2, Mod = 998244353;
int n, m, P[N];
long long TotSum, Res;
int nn, ts, L[N], R[N], W[N];
int Fen[N], Par[N], St[N], Fn[N], Hd[N], SM[N];
int L2[N], R2[N], W2[N];
int Find(int v)
{
return (P[v] < 0 ? v : (P[v] = Find(P[v])));
}
void DFSBLD(int v)
{
St[v] = ts ++;
if (R[v])
{
Par[R[v]] = v;
Hd[R[v]] = Hd[v];
DFSBLD(R[v]);
}
if (L[v])
{
Par[L[v]] = v;
Hd[L[v]] = L[v];
DFSBLD(L[v]);
}
Fn[v] = ts;
}
inline void AddFen(int i, int val)
{
for (i ++; i < N; i += i & -i)
Fen[i] += val;
}
inline int GetFen(int i)
{
int rt = 0;
for (i ++; i; i -= i & -i)
rt += Fen[i];
return (rt);
}
inline int GetFen(int l, int r)
{
return (GetFen(r - 1) - GetFen(l - 1));
}
inline void Add(int i, int val)
{
for (i ++; i < N; i += i & -i)
{
SM[i] += val;
if (SM[i] >= Mod)
SM[i] -= Mod;
}
}
inline int Get(int i)
{
int rt = 0;
for (i ++; i; i -= i & -i)
{
rt += SM[i];
if (rt >= Mod)
rt -= Mod;
}
return (rt);
}
inline int Get(int l, int r)
{
int rt = Get(r - 1) - Get(l - 1);
if (rt < 0) rt += Mod;
return (rt);
}
inline void Revert(int v, int val)
{
AddFen(St[v], val);
while (true)
{
if (val == 1)
{
TotSum += Get(St[Hd[v]], St[v]);
if (TotSum >= Mod) TotSum -= Mod;
}
else
{
TotSum -= Get(St[Hd[v]], St[v]);
if (TotSum < 0) TotSum += Mod;
}
v = Par[Hd[v]];
if (!v) break;
if (val == 1)
TotSum = (TotSum + GetFen(St[R[v]], Fn[R[v]]) * 1LL * W[v]) % Mod;
else
TotSum = (TotSum + GetFen(St[R[v]], Fn[R[v]]) * (Mod - 1LL) % Mod * W[v]) % Mod;
if (val == 1)
Add(St[v], W[v]);
else
Add(St[v], Mod - W[v]);
}
}
inline void Input()
{
memset(P, -1, sizeof(P));
vector < tuple < int , int , int > > E;
for (int i = 0; i < m; i ++)
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
assert(1 <= a && a <= n);
assert(1 <= b && b <= n);
assert(1 <= c && c <= (int)(1e8));
E.push_back(make_tuple(c, a, b));
}
int _n = n; nn = n * 2 - 1;
sort(E.begin(), E.end());
for (int i = 0; i < m; i ++)
{
int v, u, w;
tie(w, v, u) = E[i];
v = Find(v); u = Find(u);
if (v == u) continue;
if (P[u] < P[v]) swap(v, u);
W[++ _n] = w % Mod;
L[_n] = u; R[_n] = v;
P[_n] = P[v] + P[u];
P[v] = _n; P[u] = _n;
}
assert(_n == nn);
Hd[nn] = nn;
DFSBLD(nn);
}
void DFSADD(int v, int tp)
{
if (v <= n)
return void(Revert(v, tp));
DFSADD(L2[v], tp); DFSADD(R2[v], tp);
}
int DFSFNL(int v)
{
if (v <= n)
return Revert(v, 1), 0;
int sz1 = DFSFNL(L2[v]); DFSADD(L2[v], -1);
int sz2 = DFSFNL(R2[v]); DFSADD(L2[v], 1);
int sz = TotSum - sz1 - sz2;
while (sz < 0) sz += Mod;
Res = (Res + 1LL * sz * W2[v]) % Mod;
return (TotSum);
}
int32_t main()
{
scanf("%d%d", &n, &m);
assert(m == n + n); // I Don't see why this should hold
Input();
memset(P, -1, sizeof(P));
vector < tuple < int , int , int > > E;
for (int i = 0; i < m; i ++)
{
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
assert(1 <= a && a <= n);
assert(1 <= b && b <= n);
assert(1 <= c && c <= (int)(1e8));
E.push_back(make_tuple(c, a, b));
}
int _n = n;
sort(E.begin(), E.end());
for (int i = 0; i < m; i ++)
{
int v, u, w;
tie(w, v, u) = E[i];
v = Find(v); u = Find(u);
if (v == u) continue;
if (P[u] < P[v]) swap(v, u);
W2[++ _n] = w % Mod;
L2[_n] = u; R2[_n] = v;
P[_n] = P[v] + P[u];
P[v] = _n; P[u] = _n;
}
assert(_n == nn);
DFSFNL(nn);
return !printf("%d\n", Res);
}