Sereja has an integer number A that doesn’t contain zeroes in its decimal form.
Also he has N integers B[1], B[2], …, B[N].
Let us first define function f for a number A as follows.
Now he has to reorder the digits of A such that f(A) is minimum.
Please help him in finding most optimal A.
A has upto 1000 digits. N=100 and B[i] is upto 10^6.
EXPLANATION:
I haven’t found solution that is better than random, because of modulo function, so the best solution would be one, that can try as many A as possible.
So we need to optimize finding F(A). We can swap two digits of |A| and calculate F(newA) in O(N) time (because we can represent A mod B as (a0*100 + a1*101 + a2*102 …) mod B = (a0*100 mod B + a1*101 mod B + a2*102 mod B …) mod B).
So we can just find some random A and then try to swap some random not equal digits and check if it is better. Then we work with new A.
Also we can try next algorithm: fix some random A and swap some digits while we can make F(A) < F(newA). Then fix some new A and do it as many times as possible.
Other greedy techniques can also be used. Also techiniques like simulated annealing and evolutionary algorithms can be used.
The blog post mentioned in the editorial presents some good points, which were probably considered by most of the top competitors at some point throughout the contest. But I also found something which I never considered before: in Java one can use threads (on Codechef). As far as I know, this is not possible in C++ (because no threading library, like pthreads is linked), but it seems that this is possible in Java (I assumed that if they’re not allowed in C++, then threads are not allowed in any other language - it seems that I’ve been wrong). I’m not sure if using more threads in Java is enough to get more processing done than in C++, but I will certainly consider it for future contests.
The java thread library gave me an effective time limit of 12.5 seconds instead of the 5 seconds. I am not sure, but C++ 11 seems to have a strong thread library and if allowed, the time limits put up can become quite silly for those who don’t use multiple threads.
With the advent of Java 8, library functions such as parallel sort and parallel streams are really looking dangerous.
However, let me emphasize that multithreading improved the score of my algorithm by just 1%. Perhaps people like mugurelionut(Who I am a fan of ) can do better with the multiple threads, but for this problem, the search space is huge coupled with many local maximas, so I doubt it.
Main idea of my solution is to reject swap of two digits faster than O(N) if its partial score on top biggest mods is worse than their sum/2. And one more idea is try only permutations with different last 6 digits. All permutations of last 6 digits could be checked in 6! log 6! time by precalculating arithmetic progressions of r[i]+k*m[i] (small m[i] should be normalized).
I did’t know about multithreading. In my opinion it will be better to forbid it due to more random in running time. And at least it will be better to announce about it =)
I write this answer in reply to @argos’s question about @rns4’s approach. I looked at many of @rns4’s submissions and my best guess is that he was able to generate the full data offline and optimize his solution parameters this way (e.g. try a lot of rand seeds for his solution, which would easily explain the big score difference). For the digits part it’s more or less easy. He extracted the length of the 1st number in a file and the first few digits (I think about 9). Then you can brute-force offline the seed of the random number generator which generates this data (I think he rightfully assumed the author used the popular MersenneTwister). You can see this submission of his, where he checks if the first 10 digits strings in one of the test files are equal to 10 digits strings he has stored in the file (my guess is that this was to verify that he got the test data generating part right): http://www.codechef.com/viewsolution/5843470
I’m not sure how he got right the generation of the B parameters, since there was a manual parameter R used in test data generation (unless R was also randomly chosen). Anyway, I think there was a lot of work in guessing the exact test data generation algorithm (given that these R parameters were involved), but it seems that it paid off.
@gkcs: How did you determine you could only make 45 swaps using your initial algorithm? And how did storing the sum of the rows increase it to 50,000 swaps?
You are absolutely right. I discovered this during the contest. I had my fingers crossed because I thought that multithreading won’t be allowed. The thread limit is 3 per core, with 4 cores available.
@gkcs: For this problem I also wouldn’t expect a score increase of more than a few (small number) of percentage points, like maybe 1-2%. But even 1-2% can make a big difference in the challenge problem rankings. Moreover, there may be other problems where using multiple threads may lead to larger improvements. Anyway, I think that the point is that it’s at least worth trying to use multiple threads. I mean - at the very least I could run the same algorithm with different parameters in multiple threads and then pick the best answer.
@gkcs: I am surprised that every submission had 4 cores available just for itself when being executed. That may be true during the contest (when maybe there weren’t a lot of other submissions made around the same time). But I’m wondering what happens during the final rejudge, when multiple submissions are re-executed in parallel. How many cores does each submission have available during the rejudge? If they run 4 submissions per 4-core machine, then a submission effectively gets only one core - in which case using threads makes less sense. But maybe they run one submission per machine?
I don’t think they run the submissions in per core. Simply because then my solution would TLE. Also the amount of memory taken by any process can be upto X. If 4 processes are run together, memory requirement may hit 4X, resulting in NZEC for 4 AC solutions.
Really good ideas there. I had also thought of extremely localized(last k digit) search, but discarding a swap halfway though is smart.
I think banning threads is also the only practical way forward. Unfortunately, how do you do so?
@mugurelionut I think banning using multiple threads is a fair way to go forward now. If the tread libraries are found to be used in the code, we can throw a compile time error.
I used the initial algorithm in some of the submissions. In fact 46 was the limit, 47 was TLE. Then i realized that only the rowsums were changing. And that saved around 1000 computations, per remainder. Simply put, the complexity went from O(N*X) to O(X). I also saw that the number of computations went even higher than a factor of 1000…but i think that is because i optimised my code.
@argos: Good question. First of all, my rand seeds were not as good as those of @rns4 (my guess is because I couldn’t test as many - I used actual submits compared to trying the seeds offline). But the answer is easy: With each submit I checked rand seeds for up to 15 different test cases. I used about 300 of the 500 submits for tuning rand seeds => I was able to test 8-9 rand seeds for each of the 500 test cases (300*15/500 = 9).
Still didn’t get =) How did you test 15 different test cases by one submit? And one more question - seems that it could take plenty of time (at least 30sec*300=2.5 hour) for mechanical work, how did you handle it?
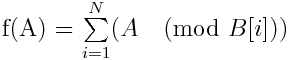
 ) can do better with the multiple threads, but for this problem, the search space is huge coupled with many local maximas, so I doubt it.
) can do better with the multiple threads, but for this problem, the search space is huge coupled with many local maximas, so I doubt it.