Problem Link
Author: Jitender
Tester: Misha Chorniy
Editorialist: Bhuvnesh Jain
Difficulty
EASY-MEDIUM
Prerequisites
Tries, Offline querying
Problem
You a given N strings and Q queries. For each query, given R and string P, you need to find the lexicographically smallest string which has the largest common prefix with S.
Explanation
Subtask 1: N, Q ≤ 1000
A simple brute force which checks each string from index 1 to R and stores the answer at each step will suffice. Below is a pseudo-code for it:
def find_max_prefix_match(string a, string b):
ans = 0
for i in [0, len(a), len(b) - 1]:
if a[i] == b[i]:
ans += 1
else:
break
return ans
def solve_query(index R, string P):
ans = ""
prefix = 0
for i in [1, n]:
if find_max_prefix_match(S[i], P) > prefix:
prefix = find_max_prefix_match(S[i], P)
ans = S[i]
else if find_max_prefix_match(S[i], P) == prefix:
ans = min(ans, S[i])
return ans
The complexity of the above approach is O(N * Q * 10) in the worst case as the maximum size of the string can be at most 10.
Subtask 2: N, Q ≤ 100000
The first idea which comes whenever you see string problems deal with prefixes if using tries or hashing. In this problem too, we will use trie for solving the problem. In case you don’t know about it, you can read it here.
Let us first try to understand how to find the lexicographically smallest string with largest common prefix with P. Assume we have the trie of all the strings build with us. We just start traversing the Trie from the root, one level at a time. Say we are at level i, we will try to greedily go to the node whose character matches with our current character, P[i]. This will help us to maximise the longest common prefix. The moment we find a mismatch, i.e. a node with current character doesn’t exist, we will try to now greedily find the lexicographically find the smallest string. For this, we just keep on traversing down the left-most node in the trie till a complete work is found.
But the above approach works when R = N in all queries as without it we can’t identify whether the string we are traversing lies in the required range of the query or not.
There are 2 different approaches to the full solution, Online solution and Offline solution.
Author/Tester Solution: Offline Approach
The problems where we can easily solve a problem given a full array but need to query for a prefix of the array can be easily handled using offline queries. The idea is as follows:
We first sort the queries based on the index of the array given. We now build out data structure (here trie), incrementally. Say the data structure is built using all the first i elements, we now answer every query which has an index as i in the query.
The pseudo-code for it is below:
queries = []
for i in [1, q]:
r, p = input()
queries.push((r, p, i))
queries.sort()
cur_index = 0
for (r, p, i) in queries:
while (cur_index <= r):
insert_element_to_ds_trie
cur_index += 1
ans[i] = query_from_ds_trie(S) //parameter r is not required
for i in [1, q]:
print ans[i]
For more details, you can refer to the author’s or tester’s solution below.
Editorialist Solution: Online Solution
The idea is simple. With every node in the trie, we keep a vector of indices which it is a part of. Using this vector we can easily decide whether the string we are traversing lies within our required range or not. But before discussing the full solution, we need to be sure that this will fit into memory limits because seeing it in a naive manner seems to consume quadratic memory as each node can have a vector of length N.
To prove that the above-modified trie also uses linear memory in order of sum of the length of strings, we see that each index appears in any vector of a node in trie as many characters are there in the string. So, out trie just uses twice the memory that the normal trie (the one in author or tester solution) uses.
Once, the above modified Trie is built, we can answer our queries easily. Since the strings are added incrementally, we are sure that the vector containing the indices will always be in sorted order. To check whether any string at a given node lies in modified range, we can use binary search. But, we can be clever here too, as the binary search will be an overkill. Since the range we want is always a prefix of the array we can just check the first element of the vector and decide whether any string lies in the required range or not. To get a clear picture of the above, you can see the below picture of the trie build from the sample case in the problem. It also contains how the answer to different queries are arrived at.
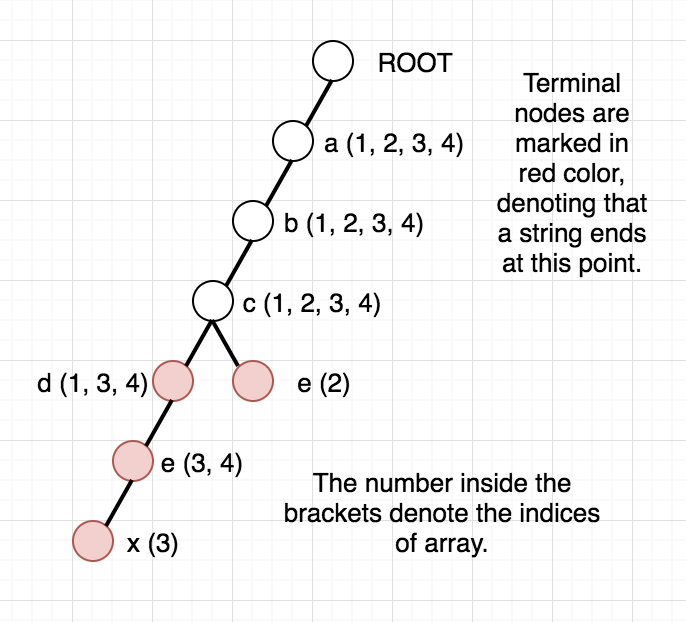
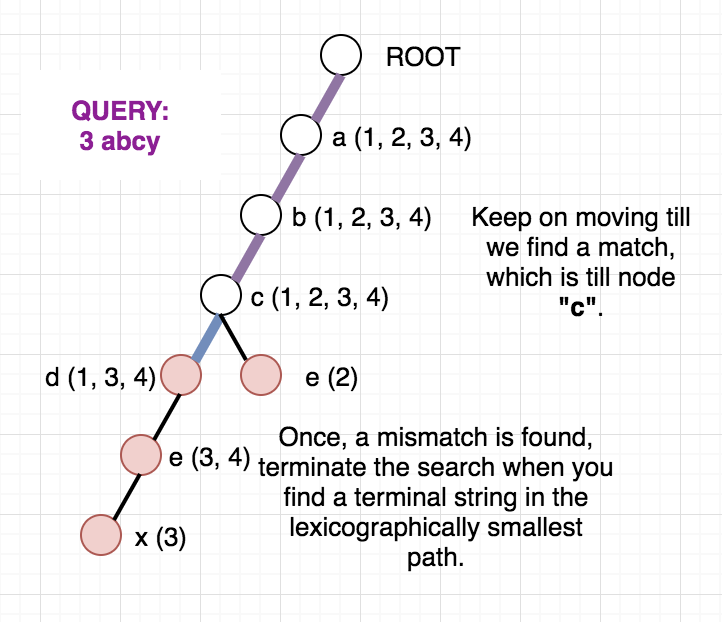
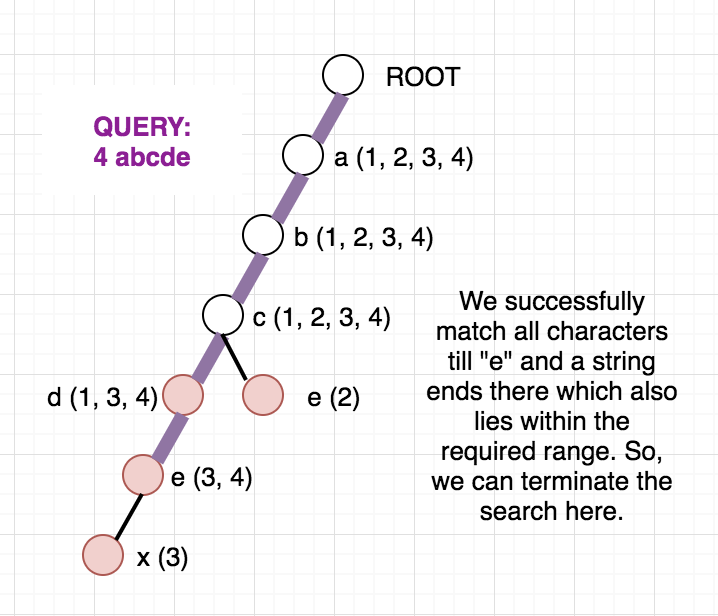
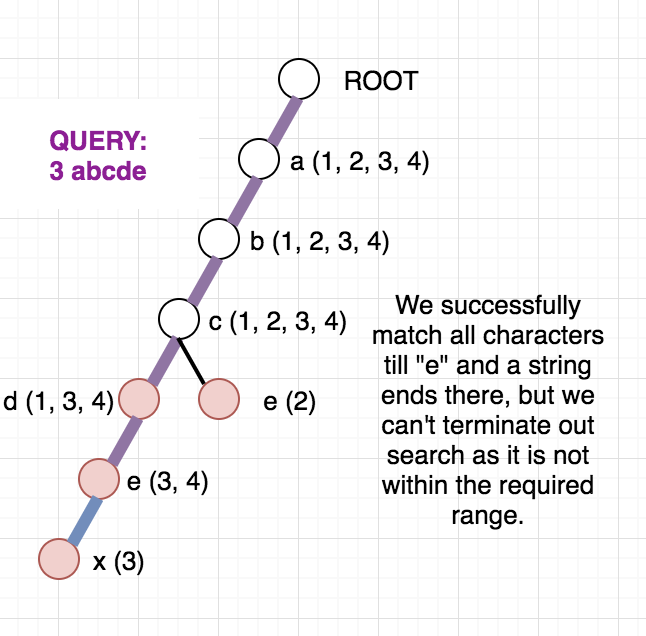
Once, you are clear with the above idea, you can see the editorialist implementation below for help.
Feel free to share your approach, if it was somewhat different.
Time Complexity
O(Q\log{Q} + \text{Sum of length of strings} * \text{ALPHABET}) for offline solution
O(\text{Sum of length of strings} * \text{ALPHABET}) for online solution
where \text{ALPHABET} = number of distinct english character (26 for this problem).
Space Complexity
O(\text{Sum of length of strings})
AUTHOR’S AND TESTER’S SOLUTIONS:
Author’s solution can be found here.
Editorialist’s solution can be found here.
