Problem Link
Author: Ivan Safonov
Tester: Hasan Jaddouh
Editorialist: Bhuvnesh Jain
Difficulty
EASY
Prerequisites
Prefix sums, Sliding Window
Problem
You are given a string S of length N and an integer K. Consider all the (N - K + 1) substrings of S of length K. Find the sum of the hamming distance between 2 consecutive substrings, where hamming distance is defined as the number of positions where the characters of two strings differ.
Explanation
For simplicity, the editorial assumes 0-based indexing of the string.
Subtask 1: T ≤ 100, N ≤ 50
For the first subtask, a naive brute force is enough to solve it. Below is a pseudo-code for it.
def hamming(string a, string b):
diff = 0
for i in [0, len(a) - 1]:
if a[i] != b[i]:
diff += 1
return diff
def solve(string s, int k):
ans = 0
for i in [0, k - 1]:
sub_1 = s.substring(i, i + k - 1)
sub_2 = s.substring(i + 1, i + k)
ans += hamming(sub_1, sub_2)
return ans
The complexity of the above approach will be O(N^2) per test case. This is not efficient for the second subtask.
Subtask 2: T ≤ 100, N ≤ 100000
For this consider, let us consider an example string S = "aabbcc" and K = 3, same as in the problem statement. Below table shows the calculation for the above naive approach.
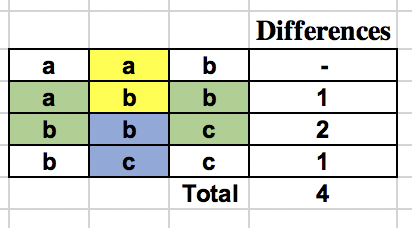
The naive approach tries to find the hamming distance of every row with the previous one and add it up. Let us see what happens when we try to find the differences along the column and them sum them up. The below table shows the calculation.
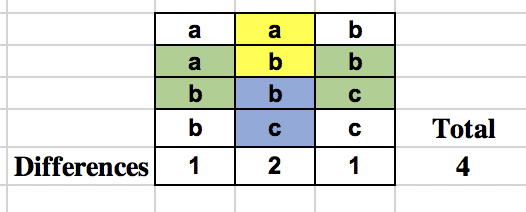
What advantage do we have while doing the above calculation in column manner? First, we don’t have to deal with full substrings. Instead, we deal with each column independently and all we care about is whether 2 consecutive characters in S are same or different.
The second one is that there is a lot of repetition in the calculation across columns, meaning that same set of different characters are repeated across many columns. For example, in the above case the pair (a, b) corresponding to letters at indices (1, 2) appears in column 1 and column 2.
So, let us store the difference array, diff, where diff[i] will be 1 if S[i] != S[i-1] else 0. using this, we can clearly see that answer for a column is just a sum of range for diff range. Using prefix sums, we can calculate the answer for every column in O(1). Then, we can add the contribution to all possible columns and find the overall answer.
Below is pseudo-code for the above approach:
def solve(string s, int k):
for i in [1, len(s) - 1]:
if s[i] != s[i-1]:
diff[i] = 1
else:
diff[i] = 0
# Build prefix sum
for i in [1, len(s) - 1]:
diff[i] += diff[i-1]
ans = 0
for i in [0, k - 1]:
ans += diff[i + (n - k)] - diff[i]
return ans
The time complexity of the above approach will be O(N + K). The pre-computation will consist of 2 parts. First, finding the diff array and then calculating the prefix sum of diff array. Each step takes O(N) complexity. Then, we find the contribution for every column, which is K in total. The space complexity will be O(N) for this approach.
You can improve the space complexity to O(1) as well using sliding-window to approach to calculate the prefix-sums on the fly and hence the answer for every column.
For more details, you can refer to the editorialist’s solution for help.
Bonus Problem
Construct a test case where the answer will overflow i.e. will not fit inside integer type and we would require the use of “long long” in C++ and “long” in Java.
Feel free to share your approach, if it was somewhat different.
Time Complexity
O(N + K) per test case.
Space Complexity
O(N)
 It had never occurred to me.
It had never occurred to me. , however, I tried solving this question using segment tree, although it ended up giving TLE error on subcase
, however, I tried solving this question using segment tree, although it ended up giving TLE error on subcase