PROBLEM LINK:
Practice
Contest: Division 1
Contest: Division 2
Setter: Данило Мочернюк
Tester: Alexey Zayakin and Yash Chandnani
Editorialist: Taranpreet Singh
DIFFICULTY:
Hard.
PREREQUISITES:
Least Common Ancestor using Euler tour or Binary lifting, Centroid decomposition. Partial Sums.
PROBLEM:
Given a tree with N nodes and an array K of length N, for each node u, calculate the maximum value D[i] such that the number of nodes at distance greater than D[i] is at least K[i].
QUICK EXPLANATION
- We decompose the tree to construct the Centroid Tree, which is guaranteed to have at most log(N) depth. For each node, we also count the number of vertices at distance x for x in its centroid subtree. We make suffix sum array to print the number of vertices at distance \geq x instantly.
- For each node, We run a binary search on the answer. Now we need to compute the number of nodes at distance x from a node.
- For each pair of node, we can split the path from u to v as path from u to LCA(u,v) to node v. Distance from u to LCA(u, v) can be computed using any LCA finding technique. From LCA(u, v), we can use the precomputation to find the number of nodes at distance greater than or equal to x. But it may include nodes which were already counted at the lower level. So, to exclude it, we count the number of nodes in subtree at each distance from the parent of the current centroid and subtract it whenever required.
- Since there are only logN levels in centroid tree, we can handle query in O(log^2(N)) due to the number of levels in centroid tree and binary search. (Assuming we use O(1) method for LCA).
EXPLANATION
First of all, subtask 1 is easy to pass. We can just, for every node, run a DFS with that node as root and count the number of nodes at each value of distance, which we can use to answer for the current node, solving the problem in O(N^2) time. We need a faster solution.
To proceed further, knowledge of Centroid decomposition is a must. Here’s an excellent resource.
Let us decompose the tree into the centroid tree. Centroid of a tree refers to any node, the removal of which divide the remains of the tree into a forest, maximum tree size being no more than half the number of nodes. This guarantees depth at most logN.
An important property of centroid tree is that the LCA of any pair of nodes u and v remain same. This allows us to split path from u to v into path from u to LCA(u,v) to node v. The distance between each pair of nodes can be calculated using preprocessing, by common LCA finding methods like using RMQ over Euler tour (preferred) or using binary lifting.
Suppose we decomposed the tree into centroid tree. For each node x in centroid tree, we can run a DFS in a subtree, calculating the number of nodes at distance \geq d for all 0 \leq d \leq s where s is the size of the subtree of u. Also, we need to calculate the number of nodes in the subtree of node u at each distance value from the parent of u in centroid tree. We shall see why.
Explaining in one line, it is because subtree of an ancestor of a node also includes the subtree of the current node. So, to exclude it, we need to calculate the number of nodes at distance di from the parent of the node too, so as to avoid double-counting of nodes.
For example, Consider tree as example with seven nodes where there’s an edge between i and i+1 nodes for every 0 \leq i < N-1. The centroid tree looks like as shown in the image.
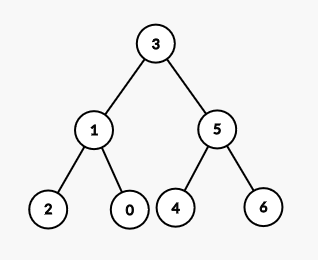
Let us count the number of nodes at distance \geq 3 from node 4. Considering the only subtree of node 4, there is no node at distance \geq 3 from node 4. Moving to its ancestor node 5 now. Distance from node 4 to 5 is 1, so, we need to count only nodes at distance \geq 3-1 = 2 from node 5. There is no such node in the subtree of node 5 at distance \geq 2 from node 5.
Climb over to its ancestor node 3. The distance of node 3 from node 4 is 1, so we need to count the number of nodes in the subtree of node 3 at distance \geq 3-1 = 2. There are four such nodes, namely node 0,1,5,6. But node 5 and node 6 are not to be considered, as they were part of the subtree of node 5 which is already considered. So, we need to exclude these two nodes. This requires to calculate the number of nodes in the subtree of a node, at each distance \geq d from the parent of the node in centroid tree. So, for subtree of node 5, there are two nodes (5 and 6) which are at distance \geq 3-dist(3,4) = 2 from node 3. So, excluding it from four nodes we found, we get two nodes at distance \geq 3 from node 4. We can easily verify its correct.
Partial sums are needed here because DFS gives us the number of nodes at distance x. To translate it into Number of nodes at distance \geq x, we take suffix sum array.
Now that we know how to count the number of vertices at distance di from any node, we can run a binary search on the maximum value of di for each node to obtain the answer.
Time Complexity Analysis
The time complexity for preprocessing takes O(N*log(N)) time for precomputing RMQ, Euler tour takes O(N) time and centroid decomposition also takes O(N) time. Running DFS over each centroid subtree takes O(N*log(N)) time as each node is present in at most logN subtrees.
For each node, the binary search takes O(logN) and within each binary search, we have to move over all ancestors of a node, which also takes O(logN) time. If LCA takes O(1) time using RMQ, we can calculate maximum distance in O(N*log^2(N)) time.
So, overall complexity comes out to be O(N*log^2(N)).
Memory complexity is O(N*log(N)).
For practice, the problems mentioned in blog would do.
AUTHOR’S AND TESTER’S SOLUTIONS:
Setter’s solution
Tester’s solution
Editorialist’s solution
Feel free to Share your approach, If it differs. Suggestions are always welcomed. ![]()