PROBLEM LINK:
Setter- Haotian Yuan
Tester- Jakub Safin
Editorialist- Abhishek Pandey
DIFFICULTY:
HARD
PRE-REQUISITES:
Centroid Decomposition, Lines in 2-D Geometry, Convex Hull
PROBLEM:
Given a weighted tree with N nodes, we have to maximize the expression \large \sum_{i=1}^{k} i*W_{v_i} where \large |W_{v_i}| can also be negative.
QUICK EXPLANATION:
Key Strategy- The first part hinting at usage of centroid decomposition or a similar strategy is intuitive. The solution is completed by correlating the reduced sub-problem (obtained after centroid decomposition) with Convex hull and lines in 2-D plane. Other implementations/correlations are possible.
We will use the divide and conquer concept of centroid decomposition first. Using this, along with some transformation, the tester reduced the problem to one of "For a given set of lines y=kx+b, which line has maximum y for a given value of x. This is easily solved by maintaining a convex hull (upper convex hull, to be more specific) and Binary search on the set of lines.
EXPLANATION:
This was the hardest problem of the set. It is expected that you’d go through the concept of centroid decomposition to understand the editorial. Also, if you are aware of how clever transformations can literally change the dimension of problem, then its a plus ![]()
The editorial will mainly discuss setter’s solution. You can open his code in another tab and correlate it with parts of editorials if you want. The idea of tester is also same.
This editorial is divided into a two sections. The first will discuss setter’s idea of the problem, and other will discuss various parts of his implementation. Some questions/hand-exercises will be left for you to enjoy as well :). Any exercise whose solution I feel should be given, will be at Chef Vijju’s Corner at the end of editorial.
1. Setter/Tester’s Idea-
The first thing to note is, there are a total of {N}^{2} possible paths (any of the N can be the source and any of the N can be the destination. Hence Total Paths=N*N={N}^{2}). This is one of the key hints that a technique like centroid decomposition should be used. However, unlike centroid decomposition’s algorithm, it can be done without needing to “actually” modify the given tree.
Now, he correlated the problem to 2-D geometry using the given transformation. Please make sure you thoroughly try to understand this part. I will explain the idea of transformation. You should then try to derive the exact transformation used by setter.
Answer= \large max(\sum_{i=1}^{i=k} i*W_{v_i}) for any path. Say, i=c is centroid (i.e. centroid is the c'th vertex in path.) W_c is weight of centroid.
Now-
Ans=\large max(\sum_{i=1}^{i=k} i*W_{v_i})=W_{v_1}+2*W_{v_2}....+c*W_c+(c+1)*W_{v_{c+1}}...k*W_{v_k}
=Sum \space of\space contribution\space of\space paths\space up\space to\space centroid\space+\space Contribution\space of\space path\space down\space from\space centroid\space
\large = \underbrace{\sum_{i=1}^{i=c} {i*W_{v_i}} } _ {Path \space to \space centroid}+\underbrace{{(\sum_{i=c+1}^{i=k} {i*W_{v_i}})}}_{Path \space down \space from \space centroid}
Let me denote W_{v_i} as W_i from here. Remember that our equation of line is y=kx+b. Now, we will split terms as-
\large =\underbrace {\underbrace {c} _ {k}*\underbrace{ \sum_{i=c}^{i=k}W_{v_i} } _ {x}+\underbrace{\sum_{i=c,j=1}^{i=k,j=(k-c)}j*W_{v_i}} _ {b}} _ {Line}+\underbrace{\sum_{i=1}^{i=c} i*W_{v_i}} _ {Calculated \space using \space DFS}
In simpler terms, the line’s equation will look like-
y=kx+b=c*(W_1+W_2+W_3....)+((k-c)*W_1+(k-c-1)*W_2.....)
This is nothing but the latter half of the path. Now, what we can do is, for each of the NlogN paths TOWARDS the centroid, we query for the line which gives maximum value for the bottom part.
We will have to deal with cases where path begins from root/centroid separately.
Now, what remains is, to solve the problem of “Given a set of lines, which line will give maximum value for a given x”
A good time to pause. Can you look at setter’s code, and look at functions dfs1 and dfs2 and deduce his transformation? Is it exactly same as I described or is it a little different?
Now, transformation done, we are yet to solve this reduced problem.What geometrical data structure can you think of, which can support insertion of new lines, removal of unwanted lines, and querying for line with highest value of y (for a given x) in atmost logN time?
The setter used a (upper) convex hull. Can you think a moment for the proof of correctness of choosing this structure? Answer will be in Chef Vijju’s corner. :). However, to help you, I have an image to give (only hints, not full answer) ![]()
The image below will also describe the steps setter used to max the hull. It goes without saying that, any unwanted or useless lines are removed from the set. You can refer to setter’s code Line 37-53
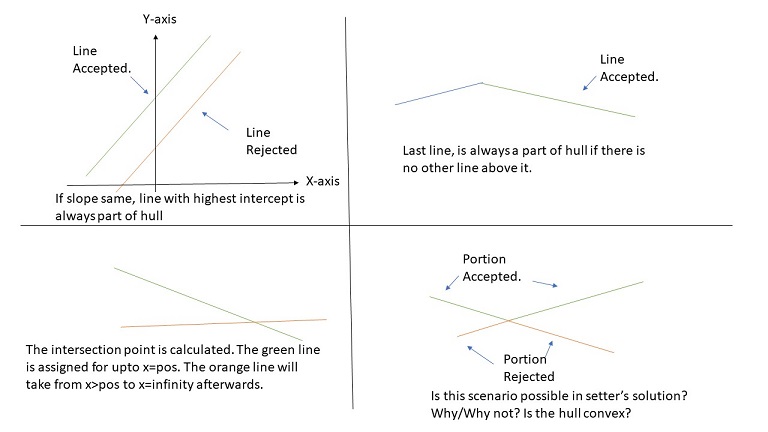
The image in fourth quadrant is a open question to you guys. Check out setter’s code and see if it allows that or not ![]()
It is very important to maintain useful lines and eliminating the useless ones from set (for memory and time efficiency).
Once the hull is made and maintained, querying is very simple. A simple use of lower_bound() function will help you get the line giving maximum y at x as we have assigned the lines a variable pos which means “This line gives greatest y till x=pos”
And with that, we are done with the hardest problem of the lunchtime!
SOLUTIONS
For immediate availability of setter and tester’s solution, they are also pasted in the tabs below. This is for your reference, and you can copy code from there to wherever you are comfortable reading them.
Click to view
#include<bits/stdc++.h>
#define LL long long
#define ll long long
#define pb push_back
#define PB pop_back
#define p push
#define P pop
#define INF 2147483647
#define ull unsigned long long
using namespace std;
const LL Linf=1ll<<61;
inline int read()
{
int x = 0, f = 1; char ch = getchar();
while (ch < '0' || ch > '9') { if (ch == '-') f = -1; ch = getchar(); }
while (ch >= '0' && ch <= '9') { x = x * 10 + ch - '0'; ch = getchar(); }
return x * f;
}
int insert_tot;
bool Qtp; //'<' type
inline LL dv(const LL&a,const LL&b){return a/b-((a^b)<0&&a%b);}
struct line
{
LL k,b; //y=kx+b
mutable LL pos; // the rightmost point y=kx+b will affect
line(LL _k,LL _b,LL _pos):k(_k),b(_b),pos(_pos){}
bool operator<(const line&a)const
{
if(Qtp)return pos<a.pos;
else return k<a.k;
}
};
typedef multiset<line>::iterator itr;
struct cvh
{
multiset<line>a;
bool inter(itr x,itr y)
{
if(y==a.end())
{
x->pos=Linf;
return false;
}
if(x->k==y->k)
{
if(x->b > y->b)x->pos=Linf;
else x->pos=-Linf;
}
else x->pos=dv(y->b-x->b,x->k-y->k);
//intersect x & y
// return true if y is useless.
return x->pos>=y->pos;
}
void insert(LL k,LL b){
// insert a line y=kx+b
itr z=a.insert(line(k,b,0)),y=z++,x=y;
while(inter(y,z))z=a.erase(z); // erase the useless line after y
if(x!=a.begin()&&inter(--x,y))inter(x,y=a.erase(y));
while((y=x)!=a.begin()&&(--x)->pos>=y->pos)
inter(x,a.erase(y)); // erase the useless line before y
}
LL query(LL x){
//query the max y for given x
Qtp=1; // change '<'
itr ret=a.lower_bound(line(0,0,x));
Qtp=0; // change '<'
// binary search
if (ret==a.end()) return -1e18;
return ret->k*x+ret->b;
}
};
const int Maxn=100005;
vector<int> G[Maxn];
int w[Maxn];
int siz[Maxn];
int n;
bool ban[Maxn];
LL ans;
void build_siz(int x,int p){
siz[x]=1;
for (int i=0;i<G[x].size();i++){
int v=G[x][i];
if (v==p || ban[v]) continue;
build_siz(v,x);
siz[x]+=siz[v];
}
}
int findc(int x,int p,int lim){
int Mx=0,Mxid=-1;
for (int i=0;i<G[x].size();i++){
int v=G[x][i];
if (v==p || ban[v]) continue;
if (siz[v]>Mx){
Mx=siz[v];Mxid=v;
}
}
if (Mx*2<=lim) return x;
return findc(Mxid,x,lim);
}
void dfs1(int x,int p,LL S1,int S2,LL S3,cvh &cv){
ans=max(ans,cv.query(S3)+S1);
for (int i=0;i<G[x].size();i++){
int v=G[x][i];
if (v==p || ban[v]) continue;
dfs1(v,x,S1+w[v]*(S2+1),S2+1,S3+w[v],cv);
}
}
void dfs2(int x,int p,LL S1,LL S2,int dep,cvh &cv){
cv.insert((LL)dep,S1);
for (int i=0;i<G[x].size();i++){
int v=G[x][i];
if (v==p || ban[v]) continue;
dfs2(v,x,S1+S2+w[v],S2+w[v],dep+1,cv);
}
}
void solve(int x){
build_siz(x,-1);
int root=findc(x,-1,siz[x]);
x=root;
ban[x]=true;
for (int i=0;i<G[x].size();++i){
int v=G[x][i];
if (!ban[v]){
solve(v);
}
}
cvh c1,c2;
c1.insert(1,w[x]);
for (int i=0;i<G[x].size();i++){
int v=G[x][i];
if (ban[v]) continue;
dfs1(v,x,w[v],1,w[v],c1);
dfs2(v,x,w[v]+w[x]*2,w[v]+w[x],2,c1);
}
for (int i=G[x].size()-1;i>=0;i--){
int v=G[x][i];
if (ban[v]) continue;
dfs1(v,x,w[v],1,w[v],c2);
dfs2(v,x,w[v]+w[x]*2,w[v]+w[x],2,c2);
}
ans=max(ans,c2.query(0));
ans=max(ans,(LL)w[x]);
ban[x]=false;
}
void Main(){
n=read();
for (int i=0;i<=n;i++) G[i].clear();
for (int i=1;i<=n;i++) w[i]=read();
for (int i=0;i<n-1;i++){
int u,v;
u=read();v=read();
G[u].pb(v);
G[v].pb(u);
}
ans=-1e18;
solve(1);
printf("%lld\n",ans);
return ;
}
int main(){
int T;
T=read();
while (T--){
Main();
}
}
Click to view
#include <bits/stdc++.h>
// iostream is too mainstream
#include <cstdio>
// bitch please
#include <iostream>
#include <algorithm>
#include <cstdlib>
#include <vector>
#include <set>
#include <map>
#include <queue>
#include <stack>
#include <list>
#include <cmath>
#include <iomanip>
#include <time.h>
#define dibs reserve
#define OVER9000 1234567890123456789LL
#define ALL_THE(CAKE,LIE) for(auto LIE =CAKE.begin(); LIE != CAKE.end(); LIE++)
#define tisic 47
#define soclose 1e-8
#define chocolate win
// so much chocolate
#define patkan 9
#define ff first
#define ss second
#define abs(x) (((x) < 0)?-(x):(x))
#define uint unsigned int
#define dbl long double
#define pi 3.14159265358979323846
using namespace std;
// mylittledoge
using cat = long long;
#ifdef DONLINE_JUDGE
// palindromic tree is better than splay tree!
#define lld I64d
#endif
vector<int> S_, par_, group_, dep_;
vector<cat> val_up_, val_down_, sum_;
void DFS(int R, auto & G, auto & par, auto & S, auto & comp, auto & bl) {
comp.push_back(R);
S[R] = 1;
ALL_THE(G[R], it) if(!bl[*it] && *it != par[R]) {
par[*it] = R;
DFS(*it, G, par, S, comp, bl);
S[R] += S[*it];
}
}
void solve(int R, auto & G, vector<cat> & V, vector<bool> & bl, cat & ret) {
vector<int> comp;
par_[R] = R;
DFS(R, G, par_, S_, comp, bl);
int sz = comp.size();
ALL_THE(comp, it) {
if(2*S_[*it] < sz) continue;
bool found = true;
ALL_THE(G[*it], jt) if(S_[*jt] < S_[*it] && 2*S_[*jt] > sz) {
found = false;
break;
}
if(found) {
R = *it;
break;
}
}
comp.clear();
par_[R] = R;
DFS(R, G, par_, S_, comp, bl);
dep_[R] = val_down_[R] = val_up_[R] = sum_[R] = 0;
for(int i = 1; i < sz; i++) {
group_[comp[i]] = (par_[comp[i]] == R) ? comp[i] : group_[par_[comp[i]]];
dep_[comp[i]] = dep_[par_[comp[i]]] + 1;
sum_[comp[i]] = sum_[par_[comp[i]]] + V[comp[i]];
val_down_[comp[i]] = val_down_[par_[comp[i]]] + dep_[comp[i]] * V[comp[i]];
val_up_[comp[i]] = val_up_[par_[comp[i]]] + sum_[comp[i]];
}
ret = max(ret, V[R]);
for(int i = 1; i < sz; i++) {
int v = comp[i];
ret = max(ret, val_down_[v] + V[R] + sum_[v]);
ret = max(ret, val_up_[v] + V[R] * (dep_[v]+1));
}
int mxdep = 0;
vector<cat> sum(sz-1), val_up(sz-1), val_down(sz-1);
vector<int> dep(sz-1), group(sz-1);
for(int i = 1; i < sz; i++) group[i-1] = group_[comp[i]];
for(int i = 1; i < sz; i++) {
dep[i-1] = dep_[comp[i]];
mxdep = max(mxdep, dep[i-1]);
}
for(int i = 1; i < sz; i++) sum[i-1] = sum_[comp[i]];
for(int i = 1; i < sz; i++) val_down[i-1] = val_down_[comp[i]];
for(int i = 1; i < sz; i++) val_up[i-1] = val_up_[comp[i]];
sz--;
for(int k = 0; k < 2; k++) {
int last_group = -1;
vector<bool> live(mxdep+2, false);
vector<int> prev(mxdep+2, 0), nxt(mxdep+2, 0);
vector<cat> val(mxdep+2, -OVER9000);
set<int> live_lst;
map<cat, pair<int, int> > vx; // vertices
live_lst.insert(0);
for(int i = 0; i < sz; i++) {
if(group[i] != last_group) {
for(int j = i-1; j >= 0; j--) {
if(group[j] != last_group) break;
// add val_up[j], dep[j]+1
int d = dep[j]+1;
if(!live[d]) {
auto it = live_lst.lower_bound(d);
it--;
int p = *it, n = nxt[*it];
if(p == 0) {
it++;
if(it == end(live_lst)) {
prev[d] = nxt[d] = 0;
live[d] = true;
val[d] = val_up[j];
live_lst.insert(d);
continue;
}
n = *it;
}
if(p != 0 && n != 0) {
// x = intersection of val[p]+p*x, val[n]+n*x
// max. x: val[p]+p*x >= val[n]+n*x
cat x = (val[p]-val[n]) / (n-p);
if(val[p]+x*p >= val_up[j]+x*d)
if(val[n]+(x+1)*n >= val_up[j]+(x+1)*d)
continue;
vx.erase(x);
}
live[d] = true;
val[d] = -OVER9000;
prev[d] = p, nxt[d] = n;
if(p != 0) nxt[p] = d;
if(n != 0) prev[n] = d;
live_lst.insert(d);
val[d] = val_up[j];
}
else if(val[d] < val_up[j]) {
int p = prev[d], n = nxt[d];
if(p != 0) {
cat x = (val[p]-val[d]) / (d-p);
vx.erase(x);
}
if(n != 0) {
cat x = (val[d]-val[n]) / (n-d);
vx.erase(x);
}
val[d] = val_up[j];
}
else continue;
// update
int p = prev[d], n = nxt[d];
while(p != 0 && prev[p] != 0) {
cat x = (val[prev[p]]-val[p]) / (p-prev[p]);
cat x_nw = (val[p]-val[d]) / (d-p);
if(x_nw > x) break;
vx.erase(x);
live_lst.erase(p);
live[p] = false;
int pp = prev[p];
prev[d] = pp;
nxt[pp] = d;
p = pp;
}
while(n != 0 && nxt[n] != 0) {
cat x = (val[n]-val[nxt[n]]) / (nxt[n]-n);
cat x_nw = (val[d]-val[n]) / (n-d);
if(x_nw < x) break;
vx.erase(x);
live_lst.erase(n);
live[n] = false;
int nn = nxt[n];
nxt[d] = nn;
prev[nn] = d;
n = nn;
}
if(p != 0) {
cat x = (val[p]-val[d]) / (d-p);
vx[x] = make_pair(p, d);
}
if(n != 0) {
cat x = (val[d]-val[n]) / (n-d);
vx[x] = make_pair(d, n);
}
}
last_group = group[i];
}
if(live_lst.empty()) continue;
auto it = vx.lower_bound(V[R]+sum[i]);
if(it == end(vx)) {
int id = *(live_lst.rbegin());
ret = max(ret, val[id] + id * (V[R]+sum[i]) + val_down[i]);
}
else {
int id = (it->ss).ff;
ret = max(ret, val[id] + id * (V[R]+sum[i]) + val_down[i]);
}
// for(int id = 0; id <= mxdep+1; id++)
// ret = max(ret, val[id] + id * (V[R]+sum[i]) + val_down[i]);
}
if(k == 1) break;
reverse(begin(sum), end(sum));
reverse(begin(val_up), end(val_up));
reverse(begin(val_down), end(val_down));
reverse(begin(dep), end(dep));
reverse(begin(group), end(group));
}
bl[R] = true;
ALL_THE(G[R], it) if(!bl[*it]) solve(*it, G, V, bl, ret);
}
int main() {
cin.sync_with_stdio(0);
cin.tie(0);
cout << fixed << setprecision(10);
int T;
cin >> T;
while(T--) {
int N;
cin >> N;
vector<cat> V(N);
for(int i = 0; i < N; i++) cin >> V[i];
vector< vector<int> > G(N);
for(int i = 0; i < N-1; i++) {
int u, v;
cin >> u >> v;
G[--u].push_back(--v);
G[v].push_back(u);
}
vector<bool> bl(N, false);
S_.resize(N);
par_.resize(N);
group_.resize(N);
dep_.resize(N);
val_up_.resize(N);
val_down_.resize(N);
sum_.resize(N);
cat ret = -OVER9000;
solve(0, G, V, bl, ret);
cout << ret << "\n";
}
return 0;}
// look at my code
// my code is amazing
Editorialist’s Solution will be put up on demand, as setter’s code is sufficiently clean and commented enough to be understood.
Time Complexity- Setter’s solution runs in O(N{Log}^{2}N)
CHEF VIJJU’S CORNER
1. Regarding the validity of hull
Click to view
The hull approach is valid, because by definition, it covers all the lines. Say, there is a point which gives better y than the edge of hull, then that case, our “Hull” isnt covering all the lines as there are portions of lines it does not cover/hover, contradicting our definition of hull.
Hence, hull is correct
2. I used “Convex hull” at some point of editorial. Am I correct in saying so? Look at quadrant 4 of image of hull and think a little ![]()
3. Misc. fact.
Click to view
@xellos0 is a great tester. He’d come up some sub-optimal solution which would pass, meaning another heapload of work for setter xD. Even after updating the test cases, he again made another sub-optimal solution to pass meaning more work for setter. And then I made a mutant of setter’s code which should fail - but it passed. Another iteration of test case generating, modification and/or remaking xD
4. BEWARE!! There is a difference between set data structure’s lower_bound and typical lower_bound function. Read it here
5. Tester’s Notes-
Click to view
Rough solution of TSUM2: Use centroid decomposition or a similar standard idea, leaving you with this subproblem:
"You have paths from a fixed root, each path goes up - note the pair (cost, length), or down - note the pair (cost, sum); you should compute the max. of cost_up+cost_down+length_up*sum_down such that the “up” and “down” paths don’t go to the same son of the root (form a simple path, paths that start in the root can be handled separately)."
This means we want a structure supporting operations “add a line y=ax+c” and “find the line y=ax+c that gives the maximum for a given x” - if e.g. “up” paths are these lines, then we have cost_down=c, sum_down=a, length_up=x, we need 2 structures for up and down paths (or a second backwards pass through the data).
This structure is basically a convex hull; when adding a line, we find the first and last segment of the convex hull this line doesn’t completely eliminate, and when searching for the maximum, it’s just binary search for the segment that contains x. Other implementations are possible.
6. Intended approaches for various subtask, other than the final one-
Click to view
Subtask-1 is for centroid decomposition and convex hull trick, but you don’t need to maintain a “dynamic” convex hull. (i.e hull doesnt support insertion or deletion of lines)
Subtask-2 is intended for any heuristic method or using convex hull trick without centroid decomposition.
7. Some problems to practice Centroid Decomposition-