[Tutorial] Lowest Common Ancestor using Euler Tour + Range Minimum Query
Hello Codechef Community,
I am back with another post which is going to be a tutorial on the Lowest Common Ancestor of two nodes in a Tree. In this post, I will be covering the concept of finding the Lowest Common Ancestor of two nodes efficiently for Multiple queries.
LCA is an easy-medium topic and has numerous applications in the field of Computer Science. The concept of the Lowest Common Ancestor is also used as a sub-routine in many problems involving trees.
There are multiple approaches to solve this problem. I will be discussing the solution involving Euler Tour and Range Minimum Query.
Prerequisites
I will try my best in explaining the concept theoretically as clear as possible but knowing the following Algorithms will be helpful.
The above concepts will not be discussed in detail, so make sure you are thorough with them.
Definition of LCA
According to Wikipedia, the lowest common ancestor(LCA) of two nodes u and v is the deepest node that has both u and v as its descendants.
For example, in the tree below, LCA(3, 4) = 2, LCA(5, 4) = 2 and LCA(5, 3) = 3.

Descendant: Node u is said to be a descendant of node v if v appears in the simple path from node u to the root node.
For example, in the tree above, descendants of 2 are {2, 3, 4, 5}, descendants of 5 are {5}.
Note:
-
The Notion of Lowest Common Ancestor also exists for Directed Acyclic Graphs (DAG), but in this post, we’ll be discussing the LCA in the context of a Tree.
-
The following conditions should be satisfied in general.
- Tree must be rooted. Otherwise, the concept of the Lowest Common Ancestor makes no sense since the tree has no fixed orientation.
- Nodes must be uniquely identified. In this post, nodes will be labelled starting from
0.
General Solution
On observation, we can notice that the lowest common ancestor of two nodes u and v is simply the node of the intersection of the paths from u and v to the root node.
For example, in the tree above, the paths from 5 and 4 to the root node have their first intersection at 2. Hence, LCA(5, 4) = 2.
Implementation of this approach can be done in many ways. One is given below.
Stack based Solution in CPP
int find_lca(int u, int v, vector<int>& parent) {
/*
* parent[i] represents parent node of node i
* Tree is rooted at 0
*/
int root = 0;
stack<int> path_from_u, path_from_v;
while(u != root) {
path_from_u.push(u);
u = parent[u];
}
path_from_u.push(u);
while(v != root) {
path_from_v.push(v);
v = parent[v];
}
path_from_v.push(v);
int lca = -1;
while(!path_from_u.empty() && !path_from_v.empty() && path_from_u.top() == path_from_v.top()) {
lca = path_from_u.top();
path_from_u.pop();
path_from_v.pop();
}
return lca;
}
Time Complexity: O(D) where D is the depth of the deepest node from root.
Clearly, this cannot be used for multiple queries unless the constraints are less.
Can we improve??
Euler Tour + Range Minimum Query
With a bit of preprocessing, we can reduce the time complexity to \log{N}. This approach involves Euler Tour and the RMQ technique. We’ll recap few things before getting into the approach.
Depth-First-Search (DFS): A graph traversing technique, where we start from the root node (or any node) and explore nodes as far as possible along each branch before backtracking.
For example, in the tree below, running dfs from the root node results in the following tour.
0 -> 1 -> 2 -> 3 -> 5 -> 4
Knowledge of DFS will be helpful in understanding Euler Tour.
Range Minimum Query (RMQ): Finds the minimal value in a sub-array of an array.
For example, consider an array of integers A = [5, 2, 1, 3, 4, 6, 2].
RMQ(3, 5) = min(A[3, ..., 5]) = 3
RMQ(0, 6) = min(A[0, ..., 6]) = 1
RMQ(0, 1) = min(A[0, ..., 1]) = 2
The problem of finding the minimum over a range can be solved using a Segment Tree or a Sparse Table. Implementation of them will not be discussed, but I will provide a brief idea of how Segment Tree works.

Basically, each non-leaf node will store the minimum of its two children.
This way, the time taken for querying minimum over a range can be reduced to O(H) where H is the height of the Segment Tree. Segment Tree is a perfect binary tree, so the height of the tree is O(\log{N})
Gear up now!! We are heading towards Euler Tour.
Euler Tour
Before defining what exactly Euler Tour is, it is better to check some examples.



Since the definition of Euler Tour from Wikipedia is not convincing (at least for some of us), we perceive it as a variant of Depth-first-search, which tries to explore every edge exactly once.
Note that Euler Tour for a Tree is performed on the set of imaginary, directed edges (marked in blue) that wrap around the given undirected edges (see above figures).
Observations
- The total number of nodes in the Euler Tour will be equal to 2\times N - 1 where N is the number of nodes in the Tree.
- A node n having c children will be visited c + 1 times.
- From 2^{nd} observation, we can state that leaf nodes are visited exactly once.
How to perform Euler Tour?
Start an Eulerian tour at the root node, traverse the imaginary edges (marked in blue) and finally return to the root node. The sequence of visited vertices gives us the Euler tour.
What do we do with the Euler tour?
While performing the tour, we record a sequence of pairs (node, depth) of visited vertices (see the following figure).
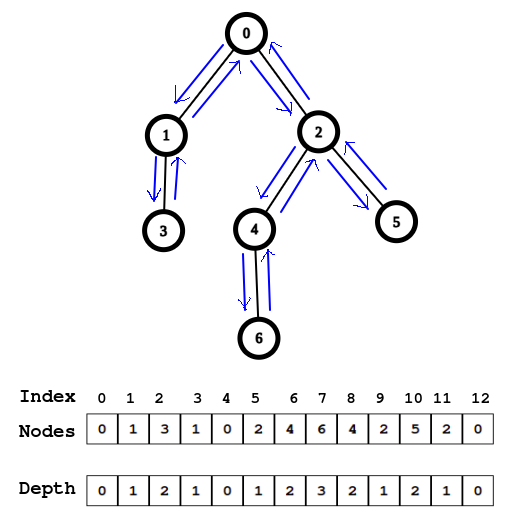
How can this information be used? Let’s find out, again with some examples.
-
Find
LCA(5, 6)from the tree diagram as well as from the information we collected in the sequence of pairs.- From the tree diagram,
LCA(5, 6) = 2. - Locate the nodes
5and6in theNodesarray. Index(5) = 10andIndex(6) = 7.- Find the index at which minimal depth appears in the sub-array
Depth[7, ..., 10] - In this case, the minimal depth in the sub-array
Depth[7, ..., 10]is1and it appears at the index9. - The node corresponding to index
9is2. - Which means, the
LCA(5, 6)is2. \ -\ (1)
- From the tree diagram,
-
Another example: Find
LCA(3, 4)using the above steps.- Locate the nodes
3and4in theNodesarray. Index(3) = 2andIndex(4) = 6.- Wait! Did you see anything?
Index(4)is not unique. So, anything will do., you can considerIndex(4) = 8as well. - Now find the index at which minimal depth appears in the sub-array
Depth[2, ..., 6]. - The minimal depth in the sub-array
Depth[2, ..., 6]is0and it appears at index4. - The node corresponding to index
4is0. - Which means, the
LCA(3, 4)is0. \ -\ (2)
- Locate the nodes
I will assume you understood finding the lowest-common-ancestor using this method. The following will discuss what exactly pre-processing does and the strategies to reduce time complexity at each step.
The Algorithm (Recap)
- Perform an Eulerian Tour on the given Tree starting from the root node.
- Keep track of the Nodes (and their depths) visited in the tour.
- For finding the
LCA(a, b), locate their indices in theNodesarray. Letindex_aandindex_bbe the indices ofaandb. - When there are two or more indices for the same node (as in example 2), choosing anyone of them will do.
- Quickly find the index at which minimal depth appears in the sub-array
Depth[index_a, ..., index_b]. Let us denote this index bylca_index. - Quickly find the node corresponding to the index
lca_indexfrom the nodes array., or simplyNodes[lca_index]is theLCA(a, b).
Wait!
Did you find out where we used the concept of Range Minimum Query?
Okay, let’s check it out.
- Quickly find the index at which minimal depth appears in the sub-array
Depth[index_a, ..., index_b]. Let us denote this index bylca_index.
How can we find the Minimum over a Sub-array Quickly ?
As I said, we’ll not be discussing them in detail. The following techniques can be used.
- Sparse Table: Can be used for finding Minimum of a Sub-array in O(1) time with a pre-processing time of O(N\log{N}).
- Segment Tree: Can be used for finding Minimum of a Sub-array in O(\log{N}) time with a pre-processing time of O(N).
In fact, we aren’t finding the Minimum over the Sub-array, we are keener about the index at which the minimal depth occurs.
Wait again!!
\rightarrow How can we perform the Step 3 i.e., finding the indices of Nodes a and b, Quickly ?
\rightarrow Will the choice of picking index(node) affect the time complexity?
We’ll answer the latter first.
\rightarrow Will the choice of picking
index(node)affect the time complexity?
Well Yes, but actually No. The following choice makes RMQ run faster (at least for Nodes at greater distances from each other).
Always pick the last encountered index of a node.
\rightarrow How can we perform the Step 3 i.e., finding the indices of Nodes
aandb, Quickly ?
We can use a dictionary that maps nodes to their corresponding last encountered indices. For specific cases where Nodes are just labelled from 0 or 1, arrays can also be used.
The Algorithm (Recap #2)
- Perform an Eulerian Tour on the given Tree starting from the root node.
- Keep track of the Nodes, their depths and the last encountered index during the tour.
- For finding the
LCA(a, b), locate their indices in theNodesarray using thelastarray. Letindex_aandindex_bbe the indices ofaandb. When there are two or more indices for the same node (as in example 2), choosing any one of them will do- Quickly find the index at which minimal depth appears in the sub-array
Depth[index_a, ..., index_b]using RMQ. Let us denote this index bylca_index. - Quickly find the node corresponding to the index
lca_indexfrom the nodes array., or simplyNodes[lca_index]is theLCA(a, b).
Implementation
This is going to be the worst part of the tutorial and excuse me for that.
Euler Tour + RMQ using Segment Tree - CPP
/*
Author: Chitturi Sai Suman
Time: 08-Sep-2021 13:08:06
*/
#include <bits/stdc++.h>
using namespace std;
class LCA {
/**
* Lowest Common Ancestor for multiple queries
* Uses Segment tree - O(N) build time + O(log N) query time
* Parameters for Constructor: vector<vector<int>> adj_list; (undirected)
*/
public:
vector<int> Nodes, Depth, last;
int segment_tree_size;
vector<pair<int, int>> segment_tree;
LCA(vector<vector<int>>& adj) {
int N = adj.size();
Nodes.resize(2 * N - 1);
Depth.resize(2 * N - 1);
last.resize(N);
int index = 0;
vector<bool> visited(N);
tour(adj, 0, 0, index, visited);
build_segment_tree();
}
void tour(vector<vector<int>>& adj, int current_node, int current_depth, int& index, vector<bool>& visited) {
Nodes[index] = current_node;
Depth[index] = current_depth;
last[current_node] = index;
visited[current_node] = true;
++index;
for(int child: adj[current_node]) {
if(!visited[child]) {
tour(adj, child, current_depth + 1, index, visited);
Nodes[index] = current_node;
Depth[index] = current_depth;
last[current_node] = index;
++index;
}
}
}
void build_segment_tree() {
int N = Nodes.size();
for(; (N & (N - 1)) != 0; N++);
Depth.resize(N, INT_MAX);
segment_tree_size = N;
segment_tree.resize(2 * N);
for(int i = 2 * N - 1; i >= N; i--) {
segment_tree[i] = make_pair(i, Depth[i - N]);
}
for(int i = N - 1; i > 0; i--) {
if(segment_tree[2 * i].second < segment_tree[2 * i + 1].second) {
segment_tree[i] = segment_tree[2 * i];
}
else {
segment_tree[i] = segment_tree[2 * i + 1];
}
}
}
pair<int, int> segment_tree_query(int node, int node_lb, int node_ub, int query_lb, int query_ub) {
if(node_lb > query_ub || node_ub < query_lb) {
return make_pair(-1, INT_MAX);
}
else if(query_lb <= node_lb && node_ub <= query_ub) {
return segment_tree[node];
}
else {
pair<int, int> left_returned = segment_tree_query(2 * node, node_lb, (node_lb + node_ub) / 2, query_lb, query_ub);
pair<int, int> right_returned = segment_tree_query(2 * node + 1, (node_lb + node_ub) / 2 + 1, node_ub, query_lb, query_ub);
if(left_returned.second < right_returned.second) {
return left_returned;
}
else {
return right_returned;
}
}
}
int find_lca(int a, int b) {
int index_a = last[a];
int index_b = last[b];
if(index_a > index_b) {
swap(index_a, index_b);
}
index_a += segment_tree_size;
index_b += segment_tree_size;
pair<int, int> returned = segment_tree_query(1, segment_tree_size, 2 * segment_tree_size - 1, index_a, index_b);
int lca_index = returned.first - segment_tree_size;
return Nodes[lca_index];
}
};
int main() {
ios_base::sync_with_stdio(false);
cin.tie(NULL);
int N = 0;
cin >> N;
vector<vector<int>> adj(N);
for(int i = 0; i < N - 1; i++) {
int a = 0, b = 0;
cin >> a >> b;
// Uncomment the following line for trees indexed from 1
// a--, b--;
adj[a].push_back(b);
adj[b].push_back(a);
}
LCA lca(adj);
int n_queries = 0;
cin >> n_queries;
for(; n_queries > 0; n_queries--) {
int a = 0, b = 0;
cin >> a >> b;
cout << lca.find_lca(a, b) << '\n';
}
return 0;
}
Special thanks to @errichto for teaching awesome concepts through his channel. I learnt Segment Tree from his video.
I learnt this concept by watching William Fiset’s Video on Lowest Common Ancestor and special thanks to him too.
Test your knowledge
Suggestions/Improvements are welcomed as always. Hope you loved it. ![]()
 !!
!!